This manual covers the configuration and operation of Develocity. It is useful for administrators and maintainers of Develocity installations.
For installation instructions, please see one of the installation guides.
Prerequisites
This manual assumes that you have previously installed Develocity using one of the above installation methods, and can access its web interface. If your installation is not at this point, please refer to the installation manual for your chosen installation type.
Application Configuration
Basic installation settings for Develocity are configured with the Helm values.yaml file. This includes how Develocity is accessed via the network and how it stores its persistent data. Configuration settings related to installation are described in the installation manuals. Additional Helm configurations are documented in the following manuals:
-
Develocity Standalone Helm Chart Configuration Guide for standalone installations
-
Develocity Kubernetes Helm Chart Configuration Guide for cluster installations
Other configuration aspects are configured via the Develocity application. Only users with the administration permission can do this, and they can do so by using the user menu in the top right of the application and choosing “Administration”. Until user accounts have been created, or in the case that no user accounts will be used, the system user can be used for this purpose.
Please read each of the following sections for information on recommended configuration.
System user password
The system user is an ever-present local user account that can be used to bootstrap the configuration of an installation or for emergency local access in case of a failure with a configured external authentication provider. The system user is hardcoded to have the Administer Develocity and Generate support bundles permissions (see Access control).
The system user has a username of system and a default password that is randomly generated for new installations.
The system user password can also be set in an unattended configuration. |
The first time a user logs in as the system user using the default password, they will be prompted to change the password. Record the new password and keep it secret since it can be used to access Develocity as an administrator. It is recommended that the system user account not be used regularly. Instead, create administrator user accounts and assign them the Administrator role. These accounts can also update the system user account password.
There are several options to find the default password:
Get the password using the Admin CLI
The Develocity Admin CLI has a command to get the default system password: (admin-cli) system get-default-system-password.
Set the password using the Admin CLI
In addition to the get-default-system-password command, the Admin CLI also has a command that sets the system password to a value you provide: (admin-cli) system reset-system-password
This can be used as an alternative to looking up the default system password, and avoids choosing a new password after the first login. The new password should be recorded and kept secret as it can be used to access Develocity as an administrator.
Get the password using kubectl
If you have kubectl installed and configured, you can view the default system password using the following command:
$ kubectl -n develocity get secret gradle-default-system-password-secret --template={{.data.password}} | base64 --decodeIf you installed Develocity in a namespace other than develocity, adjust the command accordingly. |
Find the default password in the app logs
The gradle-enterprise-app-* pods log the system password on startup when the default system password is used. It can be found by searching for Using default system password:.
While kubectl logs can be used to get the app logs, it does not have an option to get the beginning of the log, only the end. As such, this method likely won’t be of much use except with an external log aggregator or viewer.
Access control
Develocity allows locally managed user accounts and permissions, and externally managed via an LDAP service or SAML 2.0 identity provider.
Initial setup can be performed by the system user. Subsequently, any user with the “Administer Develocity” permission can configure access control by using the user menu in the top right of the application to access “Administration” and then “Access control”.
The following table describes Develocity permissions and lists the corresponding configuration file values:
|
Permission |
Config value |
Description |
|
View build scans and build data |
|
Allows viewing of build scans and associated build data |
|
Publish build scans |
|
Allows publishing of build scans |
|
Access build data via the API |
|
Allows access to the Develocity API |
|
Use Test Distribution |
|
Allows use of Test Distribution |
|
Use Predictive Test Selection |
|
Allows use of Predictive Test Selection |
|
Read build cache data |
|
Allows reading of build cache data |
|
Read and write build cache data |
|
Allows reading and writing of build cache data |
|
Read build cache data and write Bazel CAS data |
|
Allows reading of build cache data as well as writing data to the content-addressable storage exposed by the build cache’s Bazel functionality. If you typically assign read-only access to the cache for developers and write access only for the CI, consider assigning developers using Bazel this permission instead. The |
|
Access all data without an associated project |
|
Allows users to access and push data that is not associated with a project |
|
Access all data with or without associated project |
|
Allow users to access and push all data for all projects, as well as data that is not associated with a project. |
|
Configure build caches |
|
Allows configuration of build cache functionality |
|
Configure projects |
|
Allows configuration of projects and project groups for project-level access control from the Administration console, or by using the Develocity API. |
|
Generate support bundles |
|
Allows the generation of support bundles |
|
Administer Develocity |
|
Allows general administration of Develocity (e.g. access control). |
| “Administer Develocity” does not imply the “Configure build caches” or “Configure projects” permissions. |
| The “Access all data without an associated project” and “Access all data with or without associated project” permissions are granted to all users automatically when project-level access control is disabled. |
Users' permissions are managed via assigning roles to them, either in Develocity or by mapping an external Identity Provider’s roles. Both methods are described later in this section.
Develocity comes with a basic set of roles pre-configured, which are shown in the table below. They should be enough for many use-cases. Custom roles can be created and managed by going to “Administration” via the top right hand user menu, then “Access control” → “Roles”, or by using unattended configuration.
|
Role |
Display name |
Description |
Permissions |
|
|
Administrator |
Administer Develocity |
Configure build caches |
|
|
CI Agent |
Use Develocity for CI builds |
Publish build scans |
|
|
Developer |
Use Develocity |
View build scans and build data |
| Users migrating from a version before 2023.1 will also have the legacy single-permission roles. However, we generally recommend using semantic roles like the ones above. |
For externally managed user accounts (LDAP or SAML 2.0), roles can be managed locally or by group/role membership defined by the provider. When using provider-defined membership, each Develocity role can be mapped to one external group/role.
| Changes to access control settings may take up to 20 minutes to propagate through the various components of Develocity. |
Anonymous access
By default, Develocity allows anonymous viewing and creation of build scans. This makes it easier to get started by reducing build configuration, but may not be suitable for your environment. Anonymous access to the built-in build cache node is not enabled by default.
Permissions for anonymous users can be changed by going to “Administration” via the top right hand user menu, then “Access control” → “Anonymous access”.
| Changes to access control settings may take up to 20 minutes to propagate through the various components of Develocity. |
| Assigning the “Configure build caches” permission to anonymous users has been deprecated in 2023.1 and removed in 2023.2. |
Authenticated build access
Builds can authenticate with Develocity by supplying an “access key”.
Please consult the Develocity Gradle Plugin User Manual or Develocity Maven Extension User Manual for guidance on how to configure builds to authenticate with Develocity.
Local users
Locally managed user accounts can be created to allow users to access Develocity. They are not mutually exclusive with externally managed user accounts and both can co-exist provided the usernames and emails are unique.
Setup
-
From the Administration page, navigate to “Access control” → “Users”
-
Click Add User.
-
Enter details for the user and set an initial password.
-
Assign the required roles for the user.
-
Click Save.
SAML 2.0
A SAML 2.0 identity provider can be configured to allow users to access Develocity using their organization credentials. User accounts for users authenticating with the SAML provider will be created on first login. A user cannot login via a SAML provider if a locally defined account exists for the same username or email.
Signing out from Develocity does not log users out of the SAML identity provider.
Setup
-
From the Administration page, navigate to “Access control” → “Identity provider”.
-
Check ”Enable external identity provider”.
-
Choose “SAML 2.0” from Identity provider type options.
-
Enter a name for the identity provider
-
Create a SAML application at your identity provider using the displayed “Service provider SSO URL” and “Service provider entity ID”.
-
Download the metadata for the SAML application from your identity provider, and select this file for the “Identity provider metadata file” field.
-
Configure signing/encryption options. (optional)
If any signing or encryption is being used, use “Download service provider config” to obtain a configuration file that will need to provided your identity provider. -
Configure Attribute mappings.
-
Configure Roles membership.
-
Click Save.
Attribute mappings
User’s “first name”, “last name” and “email” attributes can be obtained from the identity provider or prompted for on first login.
To obtain an attribute from the identity provider, select “Manage in identity provider” for the attribute and specify the name of the SAML attribute that will provide the value. Attribute changes made at the SAML identity provider will only take affect after either a user initiated logout, administrator force logout, or session expiry.
Locally managed attributes can be updated for a user by an administrator.
Roles
User role membership can be defined by the identity provider or managed locally.
To use identity provider specified role membership, select “Defined by identity provider” in the “Role membership” section. The name of the SAML attribute that defines the roles for a user must be specified, along with the values to map to Develocity access roles.
When using “Defined by Develocity” as the “Role membership” option, the default roles for users can be specified. Users will be assigned the default roles when they first sign in. Changing the default roles will change the role membership of users with default roles enabled. Administrators can change role membership for individual users after they have signed in for the first time, including whether the default roles should be enabled for the user.
LDAP
An LDAP identity provider can be configured to allow users to access Develocity using their organization credentials. User accounts for users authenticating with the LDAP identity provider will be created on first login.
A user cannot login via an LDAP provider if a locally defined account exists for the same username or email.
Setup
-
From the Administration page, navigate to “Access control” → “Identity provider”
-
Check ”Enable external identity provider”
-
Choose “LDAP” from Identity provider type options
-
Complete the connection details for your LDAP provider.
-
Configure user attributes (described below)
-
Configure role management (described below)
-
Click Save.
Attribute mappings
There are five required fields in Develocity: “username”, ”first name”, “last name”, “email“, and “UUID”. These fields are required to be mapped to fields in your LDAP identity provider.
| Commonly, the “UUID” attribute is “entryUUID”, however for LDAP providers where this is missing, another sensible unique persistent ID should be used. For Active Directory, this is usually called “objectGUID”. |
Roles
User role membership can be defined by the identity provider or managed locally.
To use identity provider specified role membership, select “Defined by identity provider” in the “Role membership” section. Details on where to find roles and how they are defined must be provided.
| For most LDAP providers it is common for the role object class to be “groupOfNames”, however for Active Directory this is usually “group”. |
When using “Defined by Develocity” as the “Role membership” option, the default roles for users can be specified. Users will be assigned the default roles when they first sign in. Changing the default roles will change the role membership of users with default roles enabled. Administrators can change role membership for individual users after they have signed in for the first time, including whether the default roles should be enabled for the user
Recursive group membership is supported, via an opt-in option.
SCIM 2.0
Develocity supports integration with other systems via the System for Cross-domain Identity Management (SCIM 2.0) protocol. This allows for automating management of users and groups.
Setup
By default, SCIM support is disabled. To enable it:
-
Navigate to the Administration dashboard.
-
Click Access control in the navigation pane.
-
Click SCIM.
-
Check Enable SCIM integration.
-
Click Generate token.
If you have enabled SCIM previously, a “Regenerate token” button appears instead. -
Copy the “Base URL” and “SCIM token” values to a secure location for later use.
-
Click Save.
A header appears alerting you to pending configuration changes. -
Click Apply, then click Apply again in the confirmation dialog.
-
In your system that uses SCIM (often an identity provider), use the “Base URL” and “SCIM token” values saved earlier to configure the SCIM integration.
Specific instructions for the following SCIM-capable systems are available:
Limitations
-
Authentication is only supported via Bearer Tokens.
-
Usernames will always be normalized to lowercase.
-
Users created via SCIM are local to Develocity and will block using that “userName” with an identity provider.
-
Identity providers create users on first login; attempts to update a user before first login will fail.
-
The following
Userattributes are supported (others may work):-
active -
emails -
id -
name.familyName -
name.givenName
-
-
The following
Groupattributes are supported (others may work):-
displayName -
id -
members
-
Azure Active Directory
This section assumes you have a pre-existing application for Develocity in Azure Active Directory, and the application is already configured for SAML single sign on. If not, configure an application before proceeding.
-
Navigate to your Develocity application in Azure Active Directory
-
Navigate to “Manage” → “Provisioning”
-
Navigate to “Manage” → “Provisioning” (again)
-
In the “Provisioning Mode” field, select “Automatic”
-
Set the “Tenant URL” field to the “Base URL” value from the Develocity application (should look like
https://«hostname»/identity/scim/v2) -
Set the “Secret Token” field to the “SCIM token” value from the Develocity application
-
Click Save.
-
Navigate to “Mappings” → “Provision Azure Active Directory Groups”
-
Set “Enabled” to “No”
-
Click Save and confirm by clicking Yes.
-
Navigate to “Provisioning”
-
Navigate to “Mappings” → “Provision Azure Active Directory Users”
-
In the “Target Object Actions” section, uncheck “Create”
-
Click Save and confirm by clicking Yes.
-
Navigate to “Provisioning”
-
In the “Settings” section, set “Provisioning Status” to “On”
-
Click Save.
| The default attribute mappings should work without modification. |
| Users who have been assigned to the application but have not yet logged in will not show in the Develocity interface and will be skipped during provisioning operations. |
| Azure Active Directory performs provisioning on a fixed cycle, which may cause noticeable delays before changes take effect. See How long will it take to provision users? for more information. |
For more information, refer to the Azure Active Directory documentation:
Okta
This section assumes you have a pre-existing app integration for Develocity in Okta, and the app integration is already configured for SAML 2.0 single sign on. If not, configure an app integration before proceeding.
| Okta requires that your DV instance use a trusted SSL certificate. |
-
Navigate to your SAML 2.0 app integration
-
Navigate to the “General” tab
-
In the “App Settings” section:
-
Click Edit.
-
In the “Provisioning” field, check “Enable SCIM provisioning”
-
Click Save.
-
-
Navigate to the “Provisioning” tab (will not be visible if you missed the previous step)
-
In the “Settings” → “Integration” section:
-
Click Edit.
-
Set the “SCIM connector base URL” field to the “Base URL” value from the Develocity application (should look like
https://«hostname»/identity/scim/v2) -
Set the “Unique identifier field for users” field to “userName”
-
In the “Supported provisioning actions” section, check Push New Users and Push Profile Updates.
-
In the “Authentication Mode” field, select “HTTP Header”
-
Set the “HTTP Header”, “Authorization”, “Bearer” field to the “SCIM token” value from the Develocity application
-
Click Test Connector Configuration.
-
Review the results and click Close.
-
Click Save.
-
-
In the “Settings” → “To App” section (will not be visible if you missed the previous step):
-
Click Edit.
-
In the “Update User Attributes” field, check Enable.
-
Click Save.
-
| The default attribute mappings should work without modification. |
| Users who have been assigned to the application but have not yet logged in may cause an error message like "Automatic provisioning of user … to app … failed: Matching user not found" to be shown. This is expected and not harmful. If you wish to clear the error, go to Okta’s “Dashboard” → “Tasks” page after the user has logged in, select the relevant app assignments, and click “Retry Selected”. |
Okta does not delete users via SCIM. Rather, it will set the active attribute to false. |
For more information, refer to the Okta documentation:
Project-level access control
Develocity supports limiting the visibility of data from certain projects to certain users. Projects can be created in Develocity, used by builds, and associated with users. Once enabled, the following user actions are limited to the projects to which the user has access:
-
Viewing build scan data, including in dashboards or via the Develocity API
-
Publishing build scans
-
Reading or writing build cache data (including Bazel cache data)
-
Using Test Distribution
-
Using Predictive Test Selection
| To use project-level access control with the build cache, you must use access keys for authentication with the build cache, not credential authentication. |
Once a build specifies a project, access to that project will be required to take any of these actions. Additionally, builds will only have access to data from their own project. For example, a build associated with project “A” will only be able to read cache entries that were stored by builds associated with project “A”.
| The Test Distribution Administration page shows usage data for all projects, regardless of a user’s access. |
Whether a user can interact with data that does not have an associated project is determined by the “Access all data without an associated project” permission.
| When project-level access control is enabled, builds that do not specify a project will only be able to publish build scans and use Develocity features if the user running the build is granted the “Allow data without an associated project” project setting. |
Develocity stores projects and project groups in the application database, rather than in the Develocity configuration file. Use database backups to restore projects and projects groups just as you would users, access keys, and other app configuration data migrated with the database.
Configuring project access
To configure access to a project in Develocity, it first has to be created.
You need to create and assign projects in Develocity before using them in your builds.
To manage projects:
-
Navigate to “Administration” via the top right hand user menu.
-
Navigate to the “Access control” page, then the “Projects” tab.
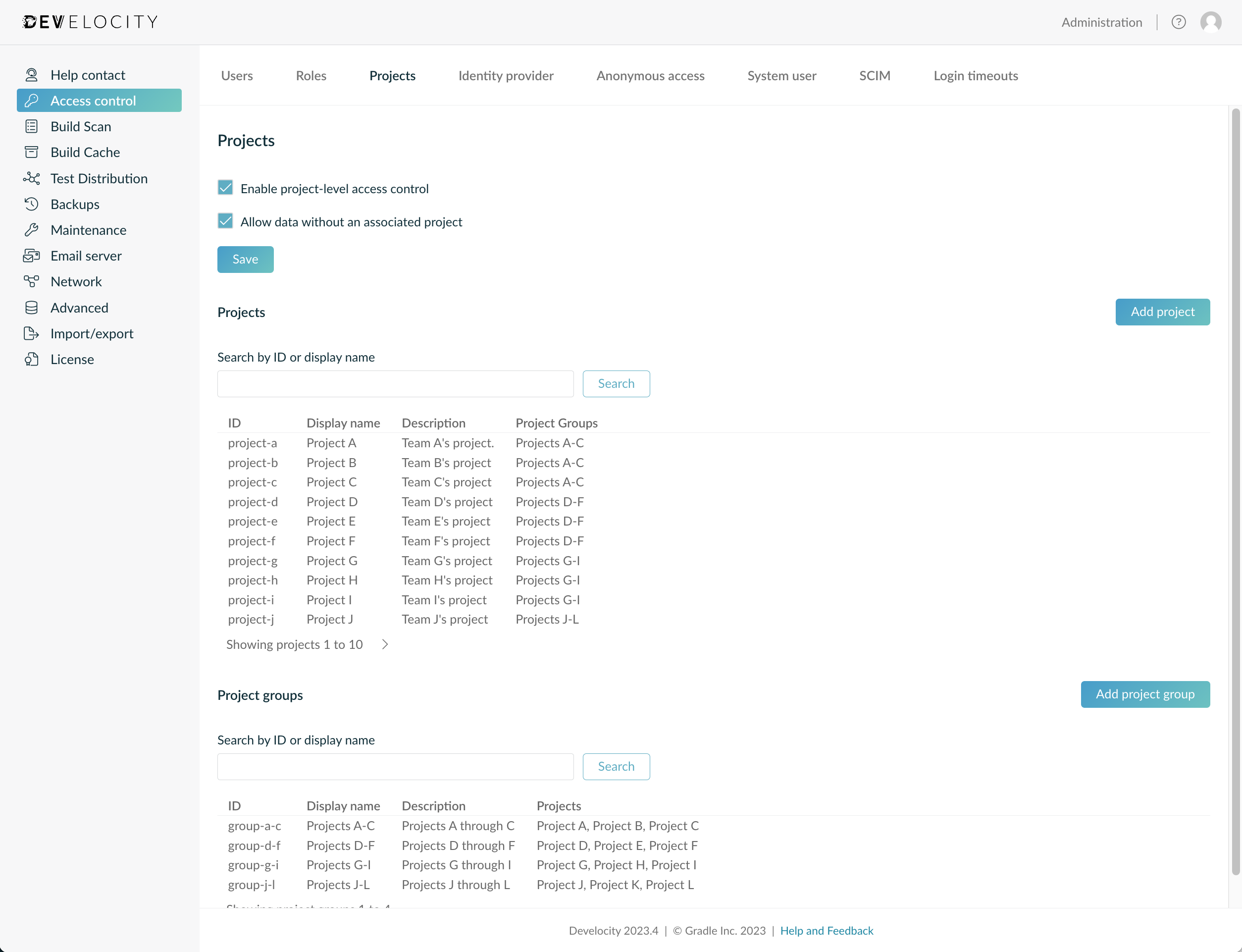
In the “Projects” section you can:
-
View and search the projects known to Develocity.
-
Create projects using the “Add project” button.
-
Edit a project, by clicking on it in the project list. The display name, description, and the project groups the project is part of can all be edited.
| The project’s ID is what builds will use to identify with the project. |
| Projects can not be deleted. |
To associate projects to users, Project Groups are used. Project groups are to projects as roles are to permissions - each group contains a set of projects, and when assigned to a user, will give the user access to all of its projects.
-
Navigate to Administration dashboard using the top right menu.
-
Click Access control in the navigation pane, then click the Projects tab.
-
Scroll to the Project Groups section.
In the “Project Groups” section you can:
-
View and search the project groups known to Develocity.
-
Create project groups using the Add project group button.
-
Edit project groups by clicking on the project in the project list.
The display name, description, the identify mapping provider, and the projects the group contains can all be edited.
Assigning project groups to users is done when editing a user, identically to how roles are assigned. Like roles, project groups can also be mapped from an external identity provider or specified in the Modify project group dialog in Develocity.
The “Access all data without an associated project” and “Access all data with or without associated project” permissions can be used to circumvent some level of per-project access control, as described in the access control section. Frequently using these permissions reduces the usefulness of project-level access control. However, they may be useful for bot accounts or CI agents, or to maintain visibility of past data that does not have an associated project.
| Changes to access control settings may take up to 20 minutes to propagate through the various components of Develocity. |
Using the API
| Project configuration using the Develocity API is in beta, and may change without notice in future releases. |
In addition to the manual configuration outlined above, the Develocity API can be used to manage projects and project groups. Project groups are still assigned to users manually or using an identity provider mapping.
The API is documented in the Develocity API documentation. All the project related API endpoints require the “Configure projects” permission.
| The API can be used to automate project creation and association (using an IdP or pre-assigned project groups) from an external source of truth, such as an internal “project registry”. |
Using in a build
For project-level access control to be useful, builds must self-identify as a project. Otherwise, they will be accessible by all users with the “Access all data without an associated project” permission. For information on how to configure a project ID, please consult the links below.
-
Apache Maven™: Develocity Maven Extension User Manual
Enabling project-level access control
By default, project-level access control is disabled and Develocity does not enforce project-level access for builds associated with a project. You can configure project access before enabling project-level access control.
To enable project-level access control:
-
Navigate to “Administration” via the top right hand user menu.
-
Navigate to the “Access control” page, then the “Projects” tab.
-
Check “Enable project-level access control”.
-
Save your settings.
Project-level access control will take effect once the configuration is applied.
| The “Administration” > “Projects” page is only visible to users with the “Configure projects” permission. |
Once you enable project-level access control, the “Allow data without an associated project” checkbox appears. The “Allow data without an associated project” setting controls whether data without an associated project can be submitted to Develocity. It is enabled by default, and we recommend keeping it that way at least until all of your builds specify a project ID.
| This setting controls whether new data without project associations will be accepted by Develocity. The “Access all data without an associated project” permission controls users' access to that data, and the ability to submit it. |
Build Scan storage
Build scans can be stored in the Develocity database, or in an object store. By default, build scans are stored in the database that Develocity is configured to connect to.
Disk space management
In most installations, storage space usage is dominated by the storage of Build Scan data. The amount of space used is dependent on how many scans are being published and how much information is being recorded for each build. When Build Scan data is stored in the database, compression and deduplication techniques are used. This means that data growth is non-linear; storing data for twice as many builds does not mean that twice the space will be required. When Build Scan data is stored in an object store, each scan is stored as a compressed, self-contained object. This makes estimation of required storage easier: twice as many scans results in roughly twice as much storage being used.
To control the amount of storage space used, we recommend that you configure Develocity to remove build scans based on their age. To avoid running out of disk space, configure automatic deletion of old build scans when the amount of free space drops below a specified percentage, as well as automatic rejection of incoming data when free space drops below a specified percentage. Additionally, the system can be configured to send warning emails when free space drops below a specified percentage.
These settings can be changed by going to “Administration” via the top right-hand user menu, then “Build Scans”.
Recommended Build Scan storage configuration
A configuration that maintains a predictable build scan retention period is:
-
Specify a maximum build scan age
-
Send a warning email when there is less than 10% of space free
-
Reject incoming data when there is less than 5% of space free
When storing scans in the database, an alternative configuration that stores as much build scan history as space permits is:
-
Do not specify a maximum build scan age
-
Automatically delete old build scans when there is less than 15% of space free
-
Send a warning email when there is less than 10% of space free
-
Reject incoming data when there is less than 5% of space free
When enabling automatic deletion of old build scans when disk space is low, be mindful that the result of another process filling the volume that Develocity is using will be that all build scan data will be deleted.
| If backups are created on the same volume, make sure to leave enough room for them in your thresholds. For example, if the total space that your backups take up is 40% of the disk, the above recommended settings would be 55%, 50% and 45%. Store backups on a separate volume to simplify space management. |
| Configuring disk space management percentage thresholds is currently only supported when using the embedded database. Please consult your database provider for monitoring and alerts on database disk space when using a user-managed database. |
| When storing Build Scans in object storage, the space used will not be taken into account in the above calculations. This means that if your installation is running low on database space, the likely cause will not be Build Scan data, so automatic deletion of build scans will not recover much space. We do not recommend setting an auto-deletion threshold when storing Build Scan data in an object store as described below. |
Build Scan object storage
It is possible to store Build Scan data in an object store, such as Amazon S3, Google Cloud Platform, and Microsoft Azure. Using object storage is a trade-off. There are a number of benefits:
-
High traffic installations typically see an improvement in build scan processing and cleanup performance.
-
Cloud-based object storage services are often highly scalable and fault-tolerant, typically more so than an individual database.
-
It is usually cheaper to store more build scans.
-
With the vast majority of Build Scan data in object storage, the main Develocity database typically requires much less storage, and the installation (for embedded databases) or the user-managed database can be provisioned with fewer resources.
-
Database backup management is easier when the database is much smaller, and backups themselves take up less space and are cheaper to store.
However, there are also downsides and limitations:
-
Installation is more complex.
-
More memory must be allocated to the Develocity application (2GB is the increase we recommend).
-
The persistent data of Develocity is no longer fully contained within a database backup, because Build Scan data is no longer stored in the database. This makes it more complicated to clone a Develocity instance.
-
Your Develocity installation should be hosted as close as possible to your object storage service. Host your Develocity instance on AWS if you’re using Amazon S3, GCP if you’re using Google Cloud Storage, or Azure if you’re using Azure Blob Storage, etc. Within the same cloud provider’s services, it should also be hosted within the same geographic region.
See the Kubernetes Helm Chart Configuration Guide or Standalone Helm Chart Configuration Guide for object storage configuration details.
There are scenarios where you must specify a custom endpoint URL for your object storage service:
-
If you need to connect to S3 directly from a VPC using a gateway VPC endpoint
-
If your object storage service is not S3 but provides an S3-compatible interface
See Custom endpoint in the Kubernetes Helm Chart Configuration Guide or Standalone Helm Chart Configuration Guide for more information.
Build Scan storage configuration
Once object storage is configured in your Helm chart, perform the following steps to store incoming Build Scan data in the store:
-
Go to the "Administration" → "Build Scans" page.
-
Select "Store incoming build scans in object storage".
-
Click "Save".
-
You will be prompted to restart to allow the configuration changes to be applied. Do not do this yet.
-
Go to the "Administration" → "Advanced".
-
Increase the "App" → "Heap memory" setting by 2048 MiB.
-
Click "Save".
-
You will be prompted to restart to allow the configuration changes to be applied. Do so.
| If you manually write a Develocity configuration file to do an unattended installation, please see the configuration reference for examples. |
If you are using EKS service account credentials, ensure that you have configured Helm with the necessary service account annotation and redeployed.
Once Develocity has restarted, all new build scans will be stored in the configured object store. Any existing build scans will be loaded from the database, and will eventually be evicted according to the configured age-based retention period. If one of your reasons for adopting object storage was to reduce the size of your database, note that you will only start to see the size of your database reducing once Build Scan data starts aging out after the retention window. To reduce the size of the database, Build Scan data needs to be deleted, and the space it took up needs to be reclaimed - a process which happens regularly, both daily and weekly.
Scheduled backups
User-managed database
When Develocity is configured to connect to a user-managed database, backups are the responsibility of the user or database provider. Please consult your database service provider or database administrator for details on how to schedule backups regularly.
Embedded database
For embedded database installations, the backup schedule and settings can be configured by going to “Administration” via the top right-hand user menu, then “Backups”.
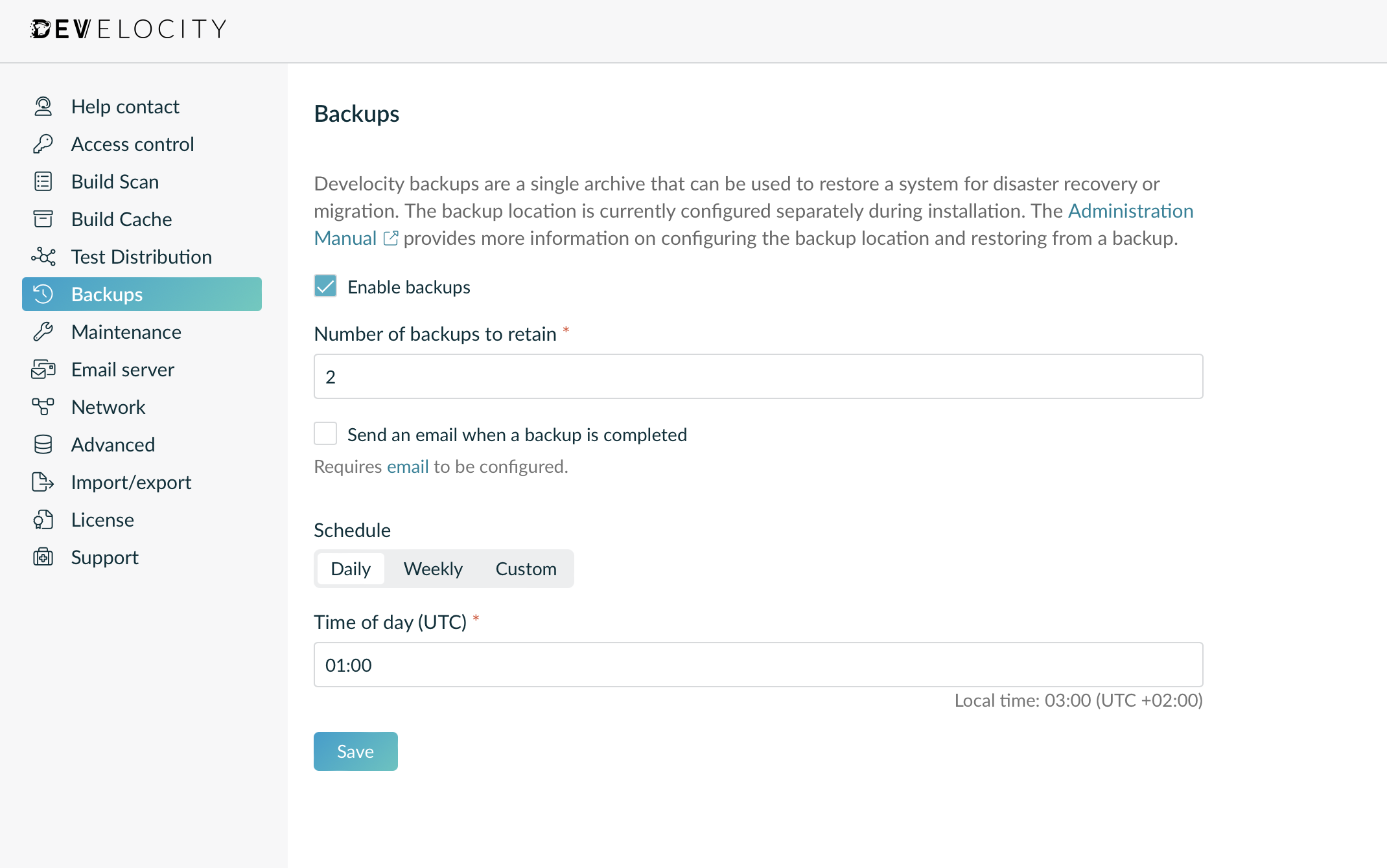
An administrator can be notified of the backup process outcome, which is particularly important in the case of failures. This requires administrator email details and SMTP server settings to be configured for the Develocity instance.
Backup location configuration
The backup location is currently configured separately during installation. For standalone installations please see the Develocity Helm Standalone Installation Manual. For Kubernetes installations please see the Develocity Helm Kubernetes Installation Manual.
See below for details on restoring backups.
Email notifications
Email server settings can be configured by going to “Administration” via the top right-hand user menu, then “Email server”.
With an email server specified, Develocity can send email notifications on completion of backups or when disk space is low. See the Disk space management and Creating backups sections for more details.
Once configured, it is possible to test email configuration by running the Develocity Admin CLI system test-notification command.
Proxy configuration
Develocity can be configured to use a proxy by going to “Administration” via the top right-hand user menu, “Network” page and then “HTTP proxy”.
With a proxy configured, Develocity will use the configured proxy to make all outbound HTTP/HTTPS requests (to external endpoints on the internet). Both HTTP and HTTPS are supported as proxy protocols.
Proxy can also be configured during installation using the unattended configuration mechanism, see the Proxy configuration section of the installation guide (the instructions are identical for standalone installations).
Untrusted SSL certificates
Develocity can be configured to trust additional SSL certificates by going to “Administration” via the top right-hand user menu, “Network” page and then “SSL trust”.
As the page notes, certificates should be added as X509 certificates in PEM format, newline seperated if there are more than one.
Additional trusted certificates can also be configured during installation using the unattended configuration mechanism, see the Untrusted SSL certificates section of the installation guide (the instructions are identical for standalone installations).
Operation
Backup and disaster recovery
Embedded database
Develocity provides system backup and restore capabilities to facilitate disaster recovery. Backups can be triggered manually or scheduled to be done automatically on a periodic basis, and require no system downtime.
The backup process produces a single compressed archive which can be used to restore all user data to a state at the time of the backup. It is highly recommended that this archive additionally be copied to an off-host location, in the case of a complete loss of the host system or volume used to store backup archives.
In addition to disaster recovery, backup archives can be used to migrate your Develocity data to a new host system. This can be useful in scenarios where a trial instance is promoted to a production one.
Creating backups
See Scheduled backups for details on configuring automated backups.
In addition to configuring automatic scheduled backups, you can trigger a manual backup at any time by running Develocity Admin CLI commands:
To create a backup, run the following command:
sudo -E java -jar gradle-enterprise-admin-<VERSION>.jar backup create
The Admin CLI responds to a successful command with the following:
Found Develocity installed in the 'develocity' namespace. Running Develocity backup Low disk space threshold is 1024MiB [BACKUP_HISTORY] Backup started Starting Postgres backup... Backing up Postgres data directory... 98 Stopping Postgres backup and copying WAL files... Compressing WAL files... 100 Adding WAL files to backup archive... Created backup: backup-20240118-174811.zip Skipping old backup cleanup as no BACKUP_RETENTION env var set Backup completed in 4 seconds [BACKUP_HISTORY] Backup completed
The output includes the name of the backup, which can be found in the /opt/gradle/backups directory. You can download the newly created backup locally by running the backup copy command. The backup archive will be copied to the directory in which the command is executed. If multiple backups exist you will be prompted to select the backup you would like to copy.
Restoring from a backup
Once a backup archive is created you may use it to restore a Develocity instance to the backup state at any time.
To restore the database from a backup, run the following command:
sudo -E java -jar gradle-enterprise-admin-<VERSION>.jar backup restore /opt/gradle/backups/backup-<DATE-TIME>.zip
The Admin CLI responds to a successful command with the following:
Found Develocity installed in the 'develocity' namespace. Copying backup Restarting deployments.apps/gradle-monitoring scaled deployments.apps/gradle-proxy scaled deployments.apps/gradle-enterprise-operator scaled ... Done. Backup will be restored.
This command requires some downtime on Develocity until the restore is finished. See the Develocity Admin CLI User Manual for more information.
| If horizontal scaling is enabled, this command will reset the current replica count on all scalable resources to the value set in the configuration UI. |
User-managed database
When data is stored in a user-managed database, backups and recovery are the responsibility of the user or database provider.
| When Develocity is using a user-managed database, customer support may not be able to assist with configuring the database for disaster recovery or restoring the database from a backup. We strongly recommend you ensure you have a working and tested disaster recovery procedure for the Develocity database. |
Creating backups
Please see your database provider for details on how to make backups and schedule them regularly.
Restoring from a backup
Restoring a database in-place
To restore a backup to the same database, overwriting the existing data, perform the following steps:
-
Stop the application by running the Develocity Admin CLI
system stopcommand. -
Follow your database provider’s instructions on restoring a backup. This may be running a tool like
pg_restoreor restoring a database snapshot, depending on your database provider and backup type. -
If you are not providing superuser credentials to Develocity, run the current database setup script used during database setup (see your installation manual) on the database and ensure that working application and migrator passwords are configured in the configuration interface or
Secretresources being used. -
Restart Develocity by running the Develocity Admin CLI
system startcommand.
Restoring to a new database instance
To restore a backup to a new database instance, perform the following steps:
-
Stop the application by running the Develocity Admin CLI
system stopcommand. -
Follow your database provider’s instructions on restoring a backup to a new instance. This may be running a tool like
pg_restoreor restoring a database snapshot, depending on your database provider and backup type. -
Configure Develocity with the new instance connection details and superuser credentials if those are being provided. This will mean re-running Helm, or updating the specified
ConfigMapandSecretresources. -
If you are not providing superuser credentials to Develocity, run the current database setup script used during database setup (see your installation manual) on the database and ensure that working application and migrator passwords are configured in the configuration interface or
Secretresources being used. -
Restart Develocity by running the Develocity Admin CLI
system startcommand.
Troubleshooting
If you experience issues with Develocity or related components, please submit a support ticket at support.gradle.com, including details of the issue and an attached support bundle.
Support Bundle
Support bundles assist our engineers in troubleshooting your issue by providing the following information about your Develocity installation:
-
Server logs
-
System performance metrics
-
Develocity database statistics
To view the “Support” page and generate support bundles, users require the “Generate support bundles” permission.
To generate a support bundle:
-
From the Administration page, click “Support” in the navigation pane.
-
Click “Generate Support Bundle”.
Develocity displays a progress bar before your browser automatically downloads the support bundle:
Downloading support bundle - this can take up to 5 minutes
It is also possible to generate a support bundle using the Develocity Admin CLI, by executing the support-bundle command. This method should be used when the Develocity user interface is not available.
Example downloading a support bundle using Admin CLI JAR file:
$ java -jar develocityctl-<VERSION>.jar \
--kube-ns=develocity \
support-bundleExample downloading a support bundle using Admin CLI Docker image:
$ docker run --rm -it \
-v "${HOME}/.kube/config:/kube-config:ro" \
-v "${HOME}/bundles:/home" \
gradle/develocityctl \
--kube-ns=develocity \
support-bundleThe Admin CLI responds to a successful command with the following and stores the generated support bundle in the directory from which the command is executed:
Support bundle saved to /home/ubuntu/support-bundle-technical_writing-20240118-183259.zip
| Generation of the support bundle may take several minutes to complete. |
Build Scan Dump
If you have questions about a particular build scan, please submit a support ticket at support.gradle.com, and attach a dump of the build scan.
To generate a build scan dump:
-
Replace
/s/with/scan-dump/in the URL for the build scan.
For example, if the URL for your build scan ishttps://ec2-54-84-194-75.compute-1.amazonaws.com/s/fmhyzs45gaepw, edit the URL tohttps://ec2-54-84-194-75.compute-1.amazonaws.com/scan-dump/fmhyzs45gaepw. -
Navigate to the edited URL.
The web browser automatically downloads the dump file. In this instance, the filename is fmhyzs45gaepw.scandump.
Licensing
Running Develocity requires a valid license, which is initially provided by the user as a license file during installation.
Develocity’s current license can be viewed by going to “Administration” via the top right-hand user menu, then “License”.
License expiration
In the event your license expires, Develocity will continue to function. However, it will be read-only. In practice, this means that the following permissions are not granted to any users:
-
Publish build scans
-
Read and write build cache data
-
Use Test Distribution
| The Read build cache data permission will continue to function as normal for users who have it. However, it will not be automatically granted to users who had "Read and write build cache data". |
In some cases, Kubernetes may fail to pull Develocity docker images and may fail to start new Develocity instances.
Full functionality will be restored if the Develocity license expiration date is updated (see below), and users' permissions will be restored automatically.
To extend or renew your Develocity license, reach out to your Gradle sales or customer success representative. If the expiration date on your license does not match the date on your contract, please submit a support ticket at support.gradle.com.
Online updates
Online installations automatically check Gradle’s license server for license updates. It does so both on startup and every hour thereafter. If a license update requires a restart to take effect, a notification is displayed to administrators.
If license checks fail for 72 hours, the instance will fail to restart.
For online installations, all that is needed to avoid expiration is to ensure that your customer success representative has extended your license. There is no need to obtain or install a new license file, as the update will be applied automatically. If the application has failed to start due to license expiration, restart it after your customer success representative has extended your license.
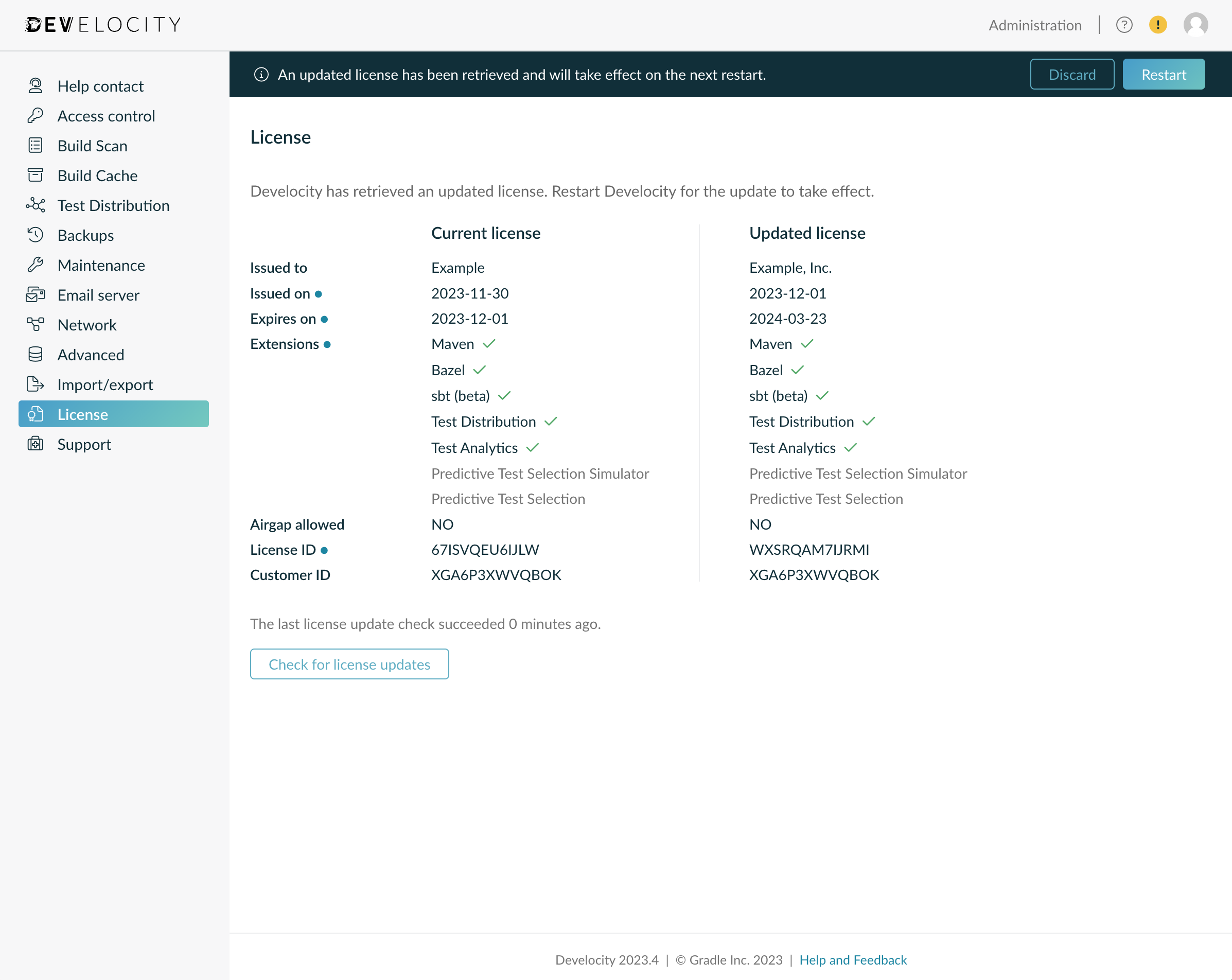
In online installations, the “Administration” section “License” tab can also be used to:
-
verify the current license’s information, such as expiration date
-
compare the current license and updated license (when an updated license has been downloaded)
-
restart Develocity to apply the updated license (when an updated license has been downloaded)
-
check whether license checks are functioning properly
-
initiate an on-demand license check
Airgap updates
Airgap installations do not receive automatic license updates. If you need an updated license file, contact your customer success representative. When you receive an updated Develocity license file, it can be applied using helm upgrade. Further details can be found in the “Changing configuration values” section of the Develocity Upgrade Guide.
Using Develocity
Build scans
A Build Scan is a shareable record of a build that provides insights into what happened and why.
For information on how to create build scans, please consult the links below.
-
Gradle: the Develocity Gradle Plugin User Manual and the Getting Started with Develocity guide for Gradle users
-
Apache Maven™: the Develocity Maven Extension User Manual and the Getting Started with Develocity guide for Maven users
-
sbt: the Develocity sbt Plugin User Manual
-
Bazel: the Develocity Bazel Configuration Guide
Compatibility between versions of Develocity and the Develocity Gradle plugin, the Develocity Maven extension, or the Develocity sbt plugin can be found here.
Build cache
Build caching dramatically decreases build times for both local development and continuous integration builds. Build caches store outputs from Gradle tasks and Maven goal executions and reuse them for later builds, rather than building the outputs again.
Develocity provides a built-in build cache node as part of each installation, and allows optionally connecting one or more remote nodes to use as discrete caches or replicas for reducing network latency.
For information on how to use the Develocity build cache, please consult the Getting Started guides for Gradle or Maven.
Build Cache administration is available at /cache-admin of your Develocity installation.
Configuration
The built-in build cache is configured with the following defaults:
-
All cache access is disabled.
-
Target cache size of 10 GiB (how much data to retain in the cache).
-
Free space buffer size of 1 GiB (how much free disk space to ensure is available at all times, reducing cache size if necessary).
-
Maximum artifact size of 100 MiB (the largest cache artifact to accept).
-
No limit on cache entry age.
To change this configuration, click the Nodes item in the left menu to access the node listing, then click View built-in node details.
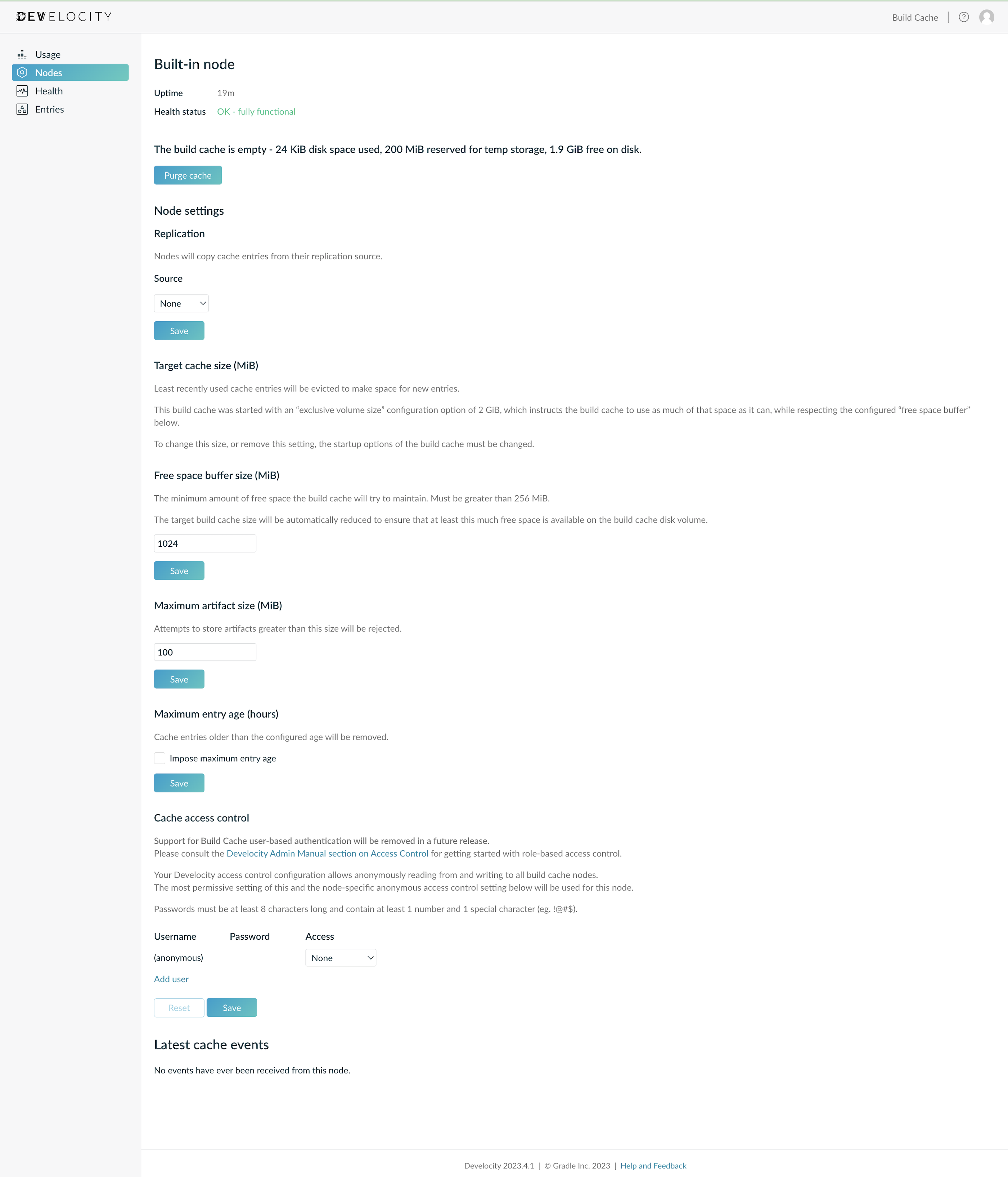
If you are using an installation method that gives the built-in build cache node an exclusive data volume (like Ship), the "Target cache size" section may instead look like this:

Access control
By default, access to the built-in cache node is disabled. There are two access control mechanisms that can be used. Which one you should use depends on the version of the Develocity Gradle plugin or Develocity Maven extension you will be using.
Version 3.11+ of the Develocity Gradle plugin and version 1.15+ of the Develocity Maven extension can authenticate to the build cache with Develocity access keys. Permissions for these users are managed via the same access control mechanism used for other functions. Users with the “Build cache read” permission can read data from any connected build cache, while users with the “Build cache write” permission can read and write data from any connected build cache.
To control access for earlier versions, separate username and password credentials can be specified in the “Build Cache” section of Develocity, in the details section for each build cache node. This section of Develocity is only accessible by users with the "Build cache admin" permission.
| Username and password credentials are deprecated and will be removed in Develocity 2024.3. |
How to configure your builds to supply credentials is described in the Develocity Gradle Plugin User Manual for Gradle, and in the Develocity Maven Extension User Manual for Maven.
Anonymous access control can also be configured using the same anonymous access control mechanism used for other functions, or by configuring node-specific anonymous permissions in the details section for each build cache node. When both are configured, the most permissive setting is used.
| When the anonymous access level is set to Read and Write, writing to the build cache does not require credentials which may allow anyone to write malicious cache entries. |
Remote nodes
Remote build cache nodes are installed separately from Develocity. They can be used to separate cache artifacts, distribute load, or improve build performance by having a better network link between the build and the node.
By connecting remote nodes to a Develocity instance, you are able to configure them centrally from Develocity, and have them replicate entries from other cache nodes.
Installation and operation of remote build cache nodes is documented in the dedicated Build Cache Node User Manual.
Connecting with Develocity
To connect a remote node to your Develocity installation, you first need to create a record for the node with Develocity by following either of these options:
Manual registration
Visit /cache-admin of your Develocity installation, and select Nodes from the left menu. In the Remote nodes > Create new node section, enter the name for your node and click Create new node.
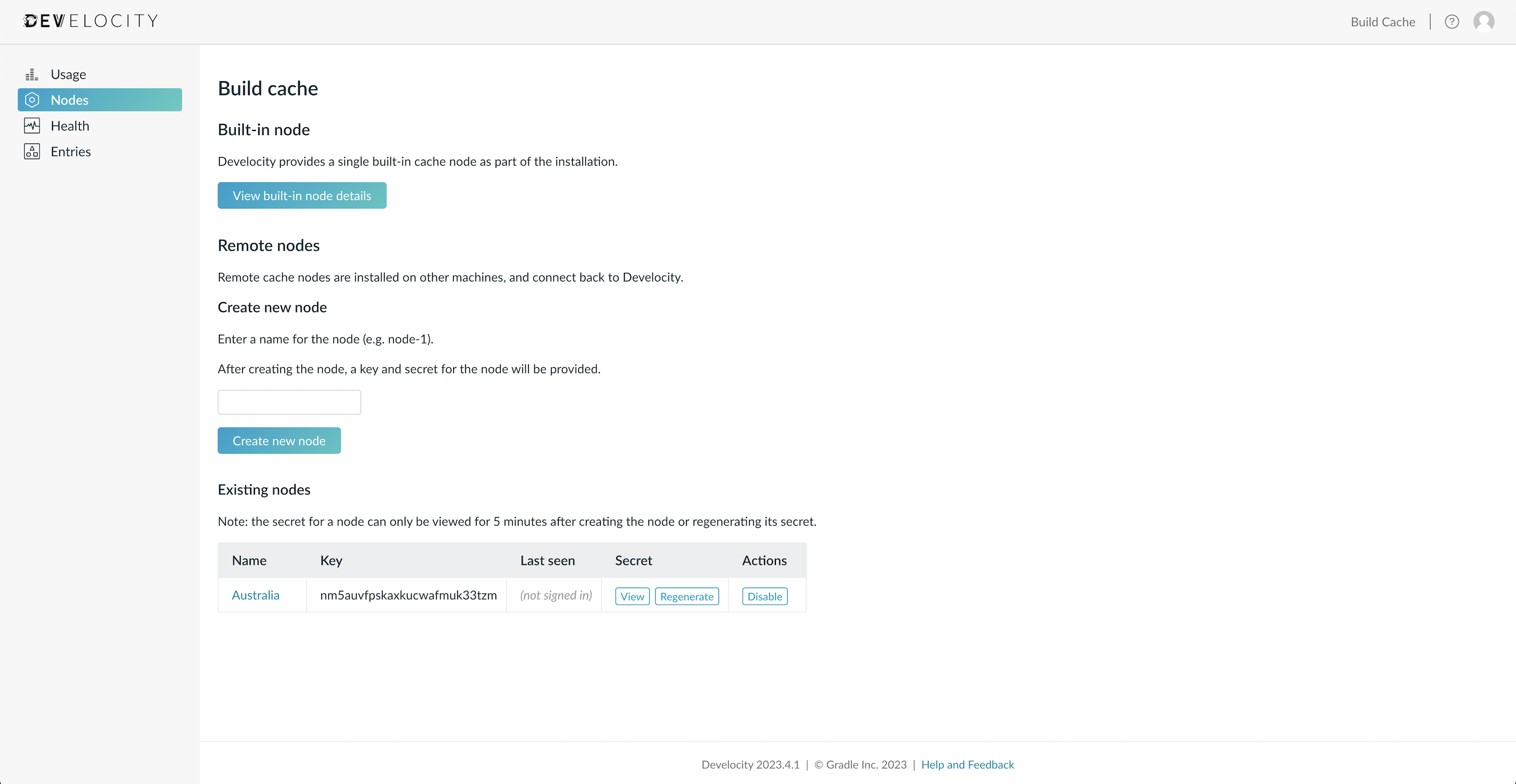
The node will now be listed in the Existing nodes section. Each node is assigned a key and a secret. To view it, click in the View button on the Secret column for the newly created node.
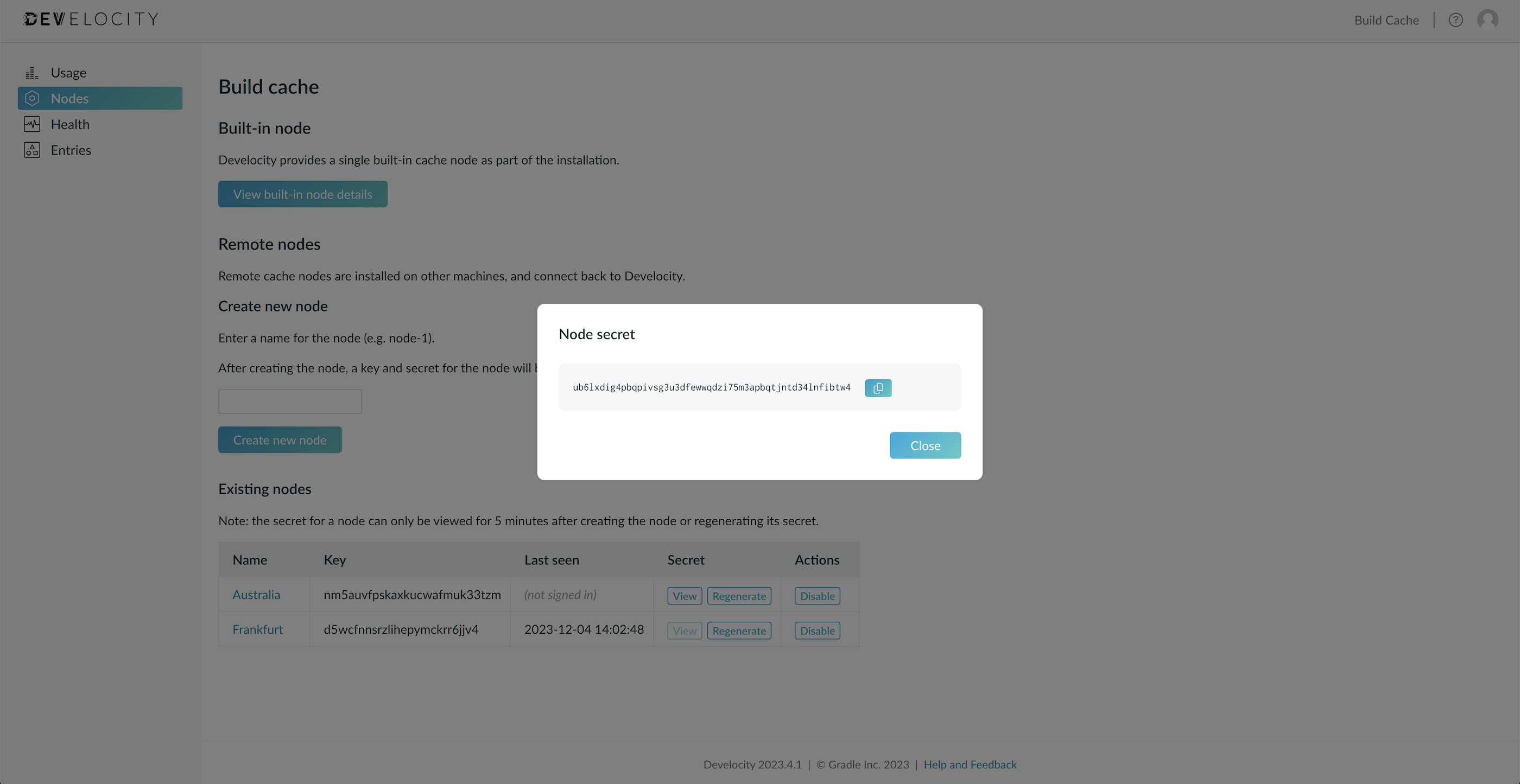
| The secret is only viewable for 5 minutes after node creation. If the node secret is lost, use the regenerate function to issue a new secret which will then be viewable for 5 minutes. |
As a last step you need to update the node configuration with the assigned key and secret.
Unattended registration
In case nodes are required to be managed by provisioning software (e.g., Terraform) Develocity offers an unattended option to register the node via the Develocity API. Please consult the access control section of the API manual on how to connect to the Build Cache section of the Develocity API.
Once you have access to the Develocity API, we can start with the registration of a node via the Develocity API.
The following example uses ge.mycompany.com as the installation host, 7asejatf24zun43yshqufp7qi4ovcefxpykbwzqbzilcpwzb52ja as the access key of the user which has the Cache admin role, and cURL as the HTTP client.
First, a new node (referred to as node-1) is registered in Develocity using the Create/Update endpoint by specifying a unique descriptive value for the name of the node, e.g.:
$ curl -X PUT https://ge.mycompany.com/api/build-cache/nodes/node-1 \
-d '{"enabled":true}' \
-H "Authorization: Bearer 7asejatf24zun43yshqufp7qi4ovcefxpykbwzqbzilcpwzb52ja" \
-H "Content-Type: application/json"If applicable, a replication configuration (in this example a preemptive replication from parent-node-1 is configured) can be specified at creation time:
$ curl -X PUT https://ge.mycompany.com/api/build-cache/nodes/node-1 \
-d '{"enabled":true,"replication":{"source":"parent-node-1","preemptive":true}}' \
-H "Authorization: Bearer 7asejatf24zun43yshqufp7qi4ovcefxpykbwzqbzilcpwzb52ja" \
-H "Content-Type: application/json"Second, a request to the secret endpoint is made using the name of the node used in the previous step. This generates a key-secret pair that the node requires for connecting to Develocity:
$ curl -X POST https://ge.mycompany.com/api/build-cache/nodes/node-1/secret \
-H "Authorization: Bearer 7asejatf24zun43yshqufp7qi4ovcefxpykbwzqbzilcpwzb52ja"{
"key":"fqysvmfd3u5dcgis5reunrxjce",
"secret":"cpgovxdo6f6phkdyxdrfzyy43q5hflatc2umzgguxv6adap2qyyi"
}As a last step you need to update the node configuration with the returned key and secret. Please consult the reference documentation of the Develocity API for further functionality with regard to node management.
Update node configuration
The node must also be configured with details of the server to connect with, including the assigned key and secret. Please consult the Develocity Registration section of the Build Cache Node User Manual for information on how to do this.
Replication
The bandwidth and latency of the network link between a build and a build cache significantly affects build performance. Replication allows users to use a cache node that they have a better network link to, while reusing artifacts from another cache node that is further away. This is particularly effective for geographically distributed teams.
The replication settings for each node can be configured via the node’s configuration page in Develocity. They can not be configured for remote nodes via the remote node’s user interface or configuration file.
A typical arrangement is to have continuous integration builds push to a cache node on a local network, and have other nodes used by developers in different locations, ideally on their local network, use it as their replication source.
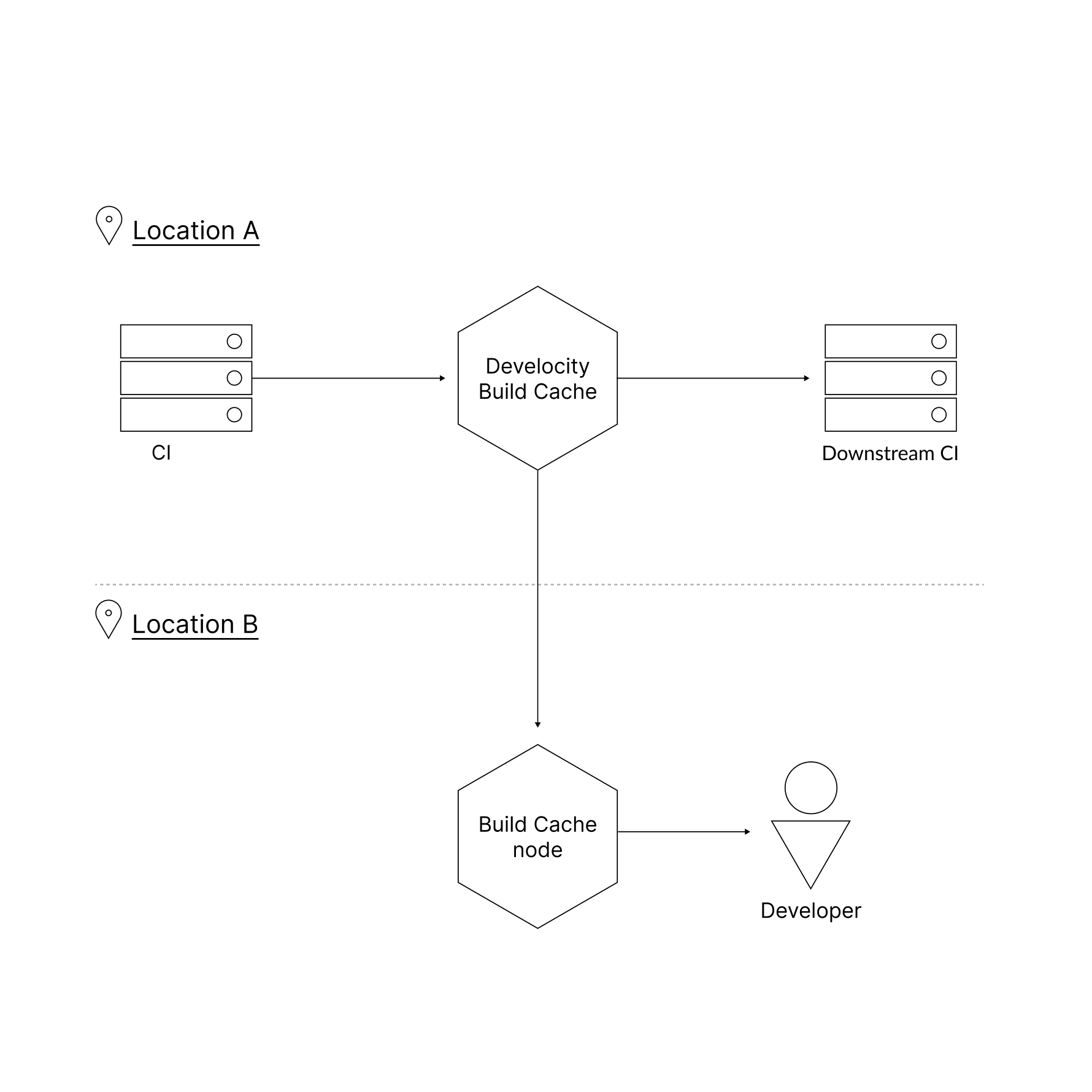
Replication is one-way (i.e. replication sources do not copy artifacts from nodes using them as a source). Furthermore, a node that is acting as a replication source cannot itself use a replication source.
| Replication is not supported with remote nodes earlier than 3.0. This setting will not be shown for such nodes. |
By default, cache entries are replicated on demand. Nodes will copy a cache entry from their replication source when that particular cache entry is requested for the first time. This avoids copying entries between nodes that will never be used, but forces builds to wait for the transfer on first use.
Preemptive replication enables better build cache performance, at the expense of more network transfer between nodes. When preemptive replication is enabled, nodes will copy cache entries from their replication source as soon as they are added. The downside of this approach is that entries may be copied that are never used. If network bandwidth usage between nodes is not a concern, this is the best configuration.
Only cache entries that are added to the replication source after the node has connected are copied preemptively. Any already existing entries will be copied on demand.
| Preemptive replication is only supported for nodes of version 4.0 or later. If the node or its replication source is older than this, replication will be on demand. |
Health monitoring
The Health page provides an overview of the operational status of all enabled build cache nodes.
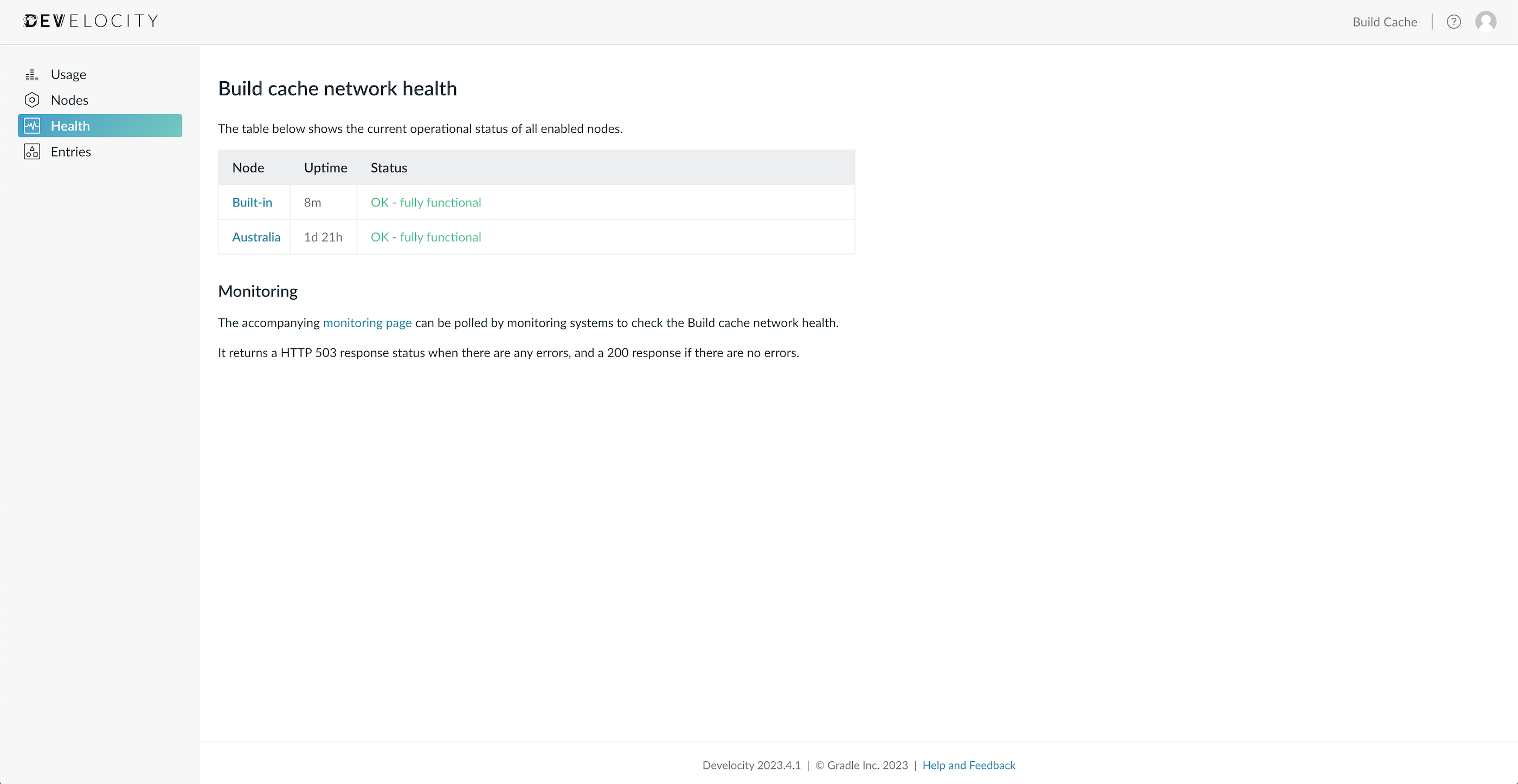
Each node may have a status of OK, WARN or ERROR. If all nodes are reported as OK, you can be assured that your build cache network is operating well.
WARN indicates that there is a non-critical issue, or that there is a problem that is expected to resolve itself soon. If the issue does not resolve itself, or for immediately critical issues, the ERROR status is used.
A monitoring tool friendly version of this page is available via the Monitoring page link towards the bottom of the page. This endpoint returns the statuses in plain text. If there are any ERROR statuses, the HTTP response status code for this page will be 503. Otherwise, it will be 200.
Test Distribution
Develocity Test Distribution takes your existing test suites and distributes them across multiple compute resources to execute them faster. It requires connecting one or more test execution “agents” to Develocity. Builds that have enabled Test Distribution connect to Develocity, which then distributes the tests to be executed on connected agents.
Connecting builds
Please consult the Develocity Test Distribution User Manual for information on build configuration.
Develocity users must be granted the “Test Distribution” access control role to be able to use Test Distribution.
| Builds and agents connect to the Develocity server using a WebSocket connection. Thus, you need to ensure WebSocket support is enabled on every load balancer or proxy that is used in between the build/agent and the Develocity server. |
The “Jobs” tab provides an overview of the currently active jobs, where each row represents a running test task or goal in a Gradle or Maven build, respectively.
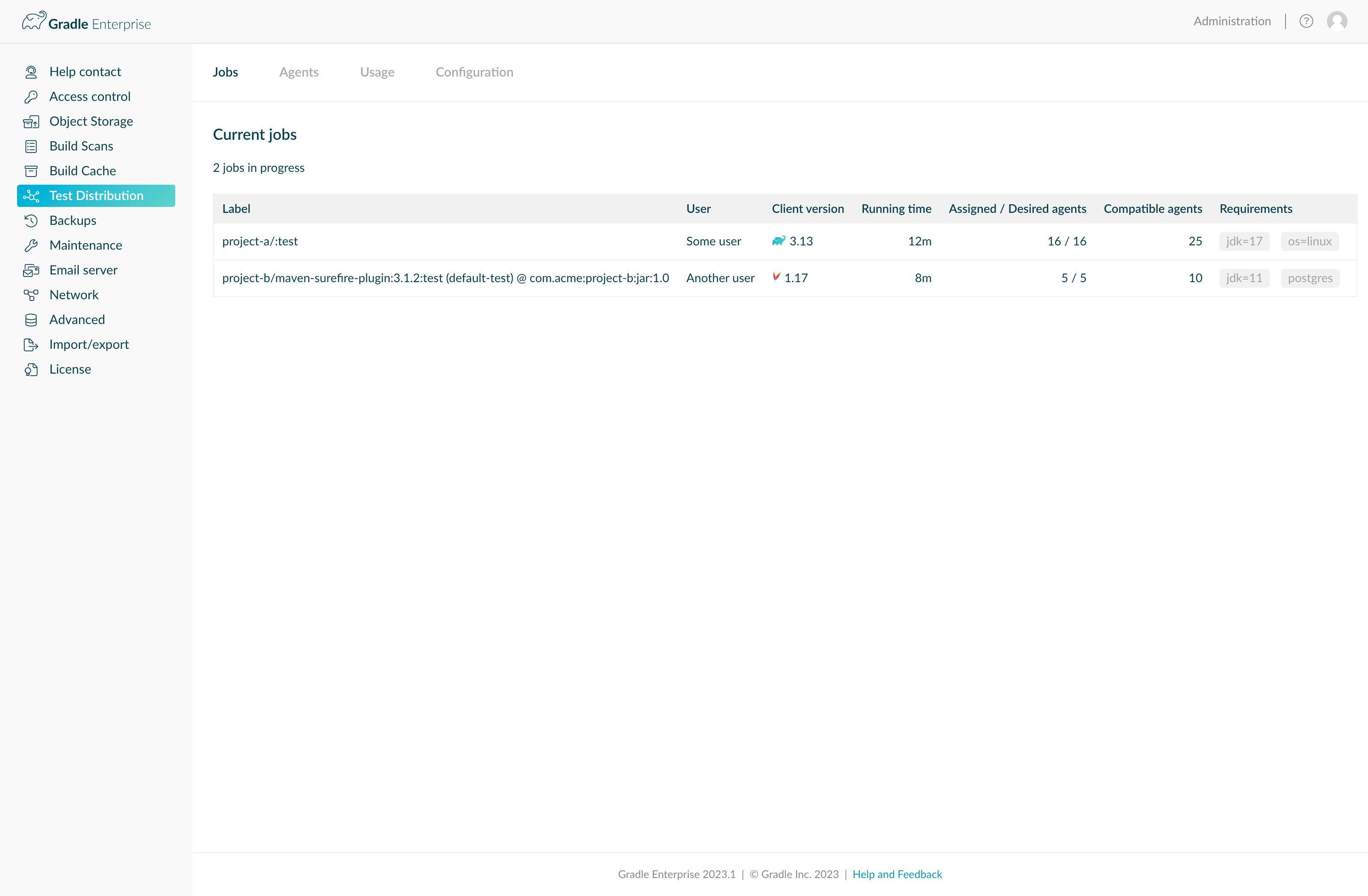
The first part of the label indicates the root project name of the build, while the second part identifies the particular task or goal. The count of assigned/desired agents shows how many agents are currently assigned to/desired by the job. More agents may be assigned as they become available. The count of compatible agents shows how many currently connected agents have capabilities that satisfy the requirements of the job.
API keys
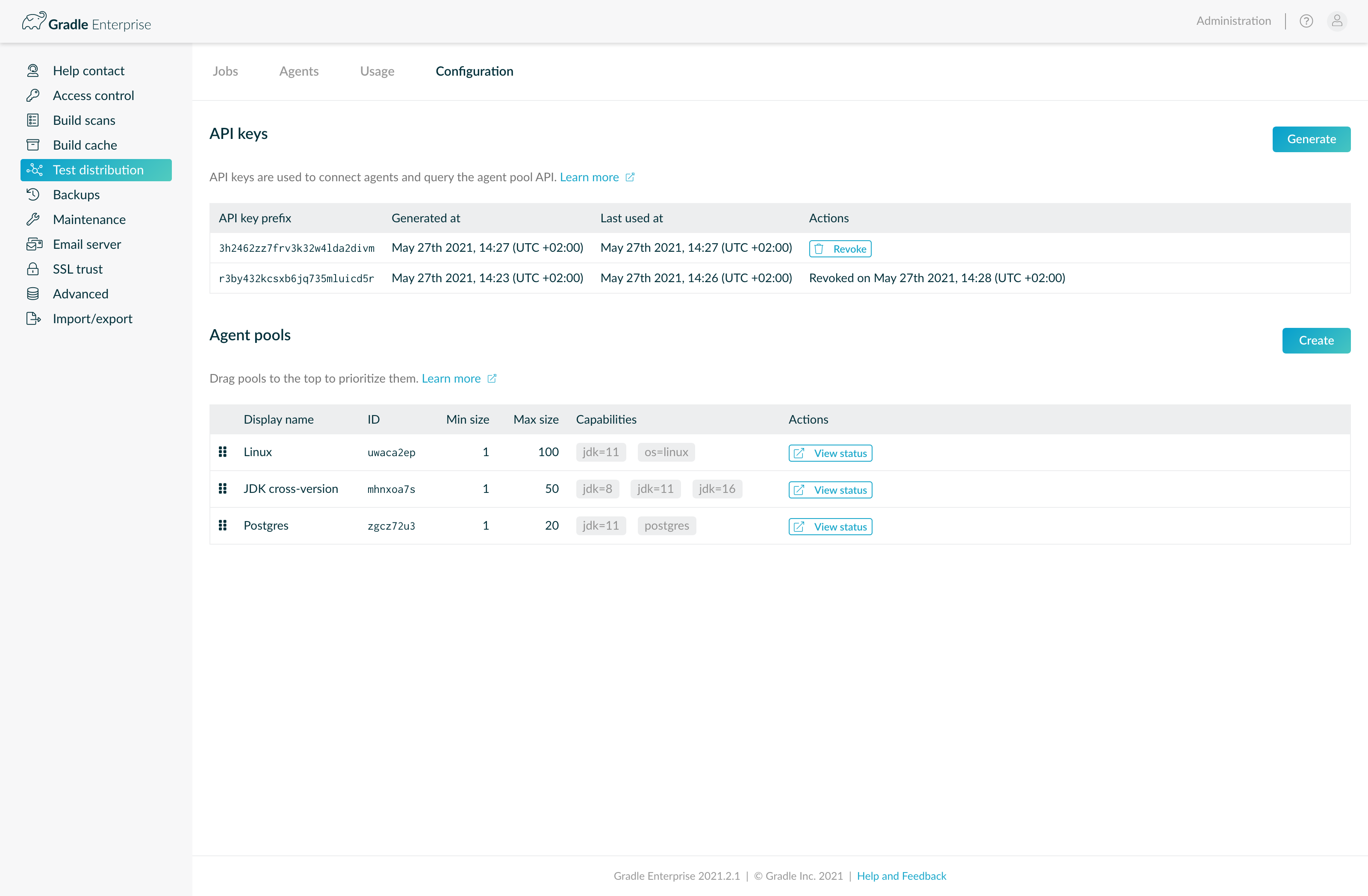
API keys are used by agents to authorize their connection to Develocity, and for authorizing connections to Test Distribution APIs provided by Develocity.
API keys can be generated on the “Configuration” tab. A single API key may be used my multiple agents. Multiple can be created to facilitate a rolling update if required. Revoking an API key prevents it from being used for future registrations and API access. Connected agents will be forcibly disconnected one hour after the API key they used to connect is revoked.
Agents
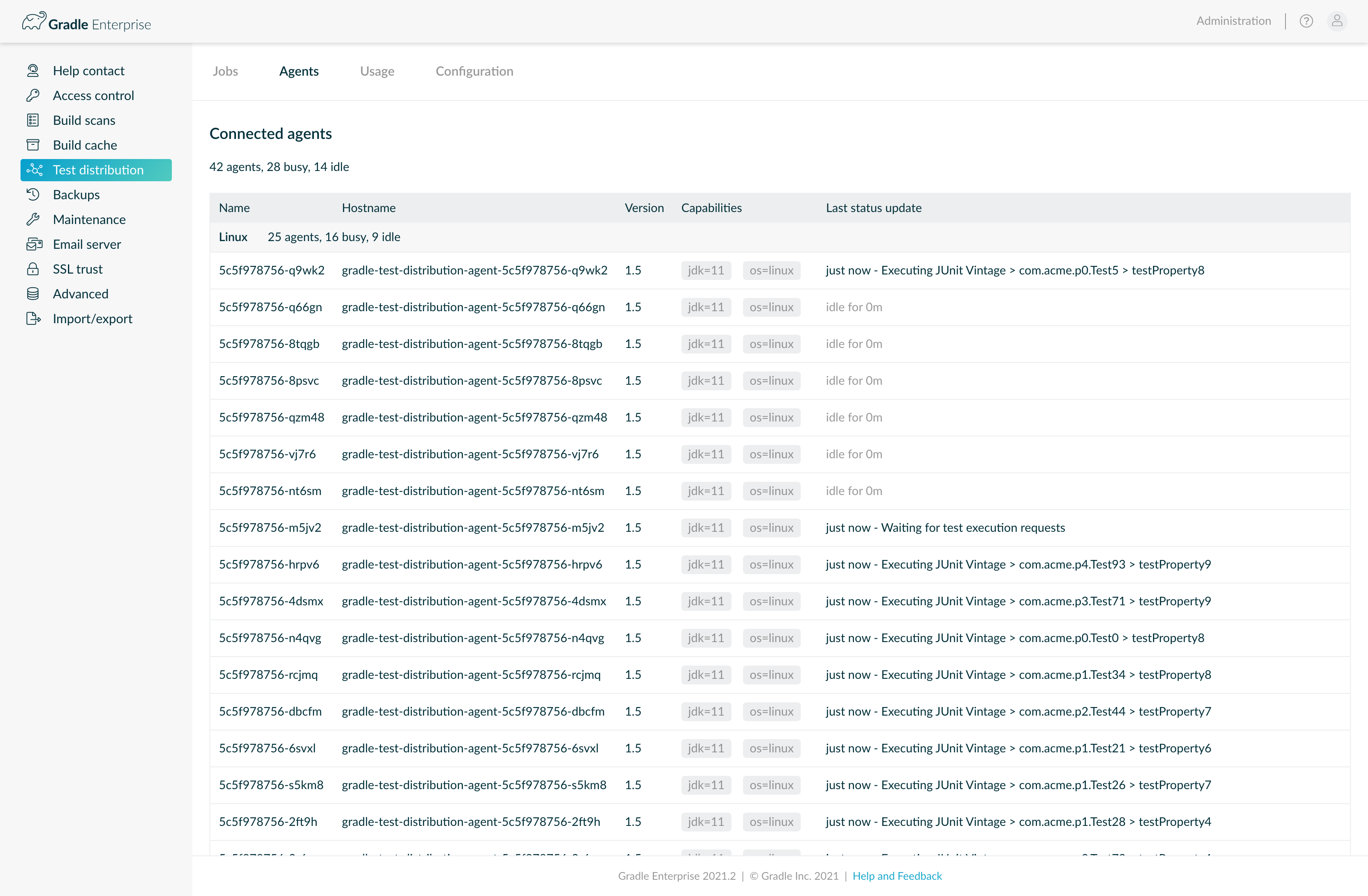
Utilizing Test Distribution requires connecting additional compute resources, called agents, to Develocity. The Test Distribution agent is available as a Docker image or standalone JAR and is easy to deploy and operate via Kubernetes or any modern compute platform. Please consult the Develocity Test Distribution Agent User Manual for more on deploying and operating agents.
The “Agents” tab shows all currently connected agents.
Auto scaling agents with pools
Agents in a pool can be scaled up and down based on demand. Each pool has a generated unique ID that is specified by an agent when connecting to indicate its pool, and can be used by compute platform auto scalers to determine the desired number of agents at any time for that pool.
| Please refer to the Develocity Test Distribution Agent User Manual for step-by-step instructions for auto scaling with Kubernetes. |

Minimum and maximum size
The minimum and maximum size of an agent pool is used to determine the desired number of agents at a given moment.
Ultimately, the actual number of agents is determined by the compute platform, which may impose incompatible limits. Where possible, ensure that the limits imposed by the compute platform are either identical to or compatible with those configured in Develocity.
To temporarily disable a pool, set both minimum and maximum to zero.
Capabilities
Agents in a pool are expected to provide a certain set of capabilities. While an agent may provide additional capabilities, it will be rejected when connecting without at least the mandatory capabilities configured on its agent pool.
While computing the number of desired agents for a pool its capabilities are matched against the requirements of the current jobs. A pool is only utilized if it satisfies all of a job’s requirements. Therefore, you should at least add a jdk=… capability to each agent pool since such a requirement is added implicitly to each job. Moreover, each agent has an implicit os=… capability which should be added to the agent pool for the sake of consistency and in case it’s an explicit requirement of any job.
Already connected agents that don’t provide all mandatory capabilities will stay connected for up to 4 hours after adding capabilities to an agent pool. Any agent in the pool that has capabilities that do not exactly match the ones of the poll is shown with a warning indicator on the “Agents” tab.
In order to add a new capability to an existing pool, it is recommended to first add the capability to all connected agents and then edit the agent pool. This way agents connecting will not be rejected while the change is being applied (e.g. due to a rolling update).
In order to remove a capability from an agent pool, we recommend to first remove the capability from the pool before removing it from connected agents. Agents in the pool that still provide the capability will no longer match the corresponding build requirement and not be assigned.
Priority
Pools with higher priority are utilized before pools with lower priority. If tests to be executed can be executed by agents from different pools, agents of the pool with the highest priority are requested. When scaling to meet demand, higher priority pools are scaled to their configured maximum before scaling lower priority pools.
You can change the priority of agent pools by dragging them on the “Configuration” tab. Pools that are higher on the list are prioritized over those below.
Deletion
Agent pools can be deleted at will when they are no longer needed. It is recommended to stop all agents in the agent pool before deleting it. Already connected agents will stay connected for up to 4 hours after deleting an agent pool. During that time they will be shown with a warning indicator on the Agents tab.
Pool status
Agent auto scaling relies on auto scaling machinery of a compute platform regularly querying Develocity for a pool’s desired size and starting/stopping agents to match the desired size.
The https://«hostname»/api/test-distribution/agent-pools/«pool-id»/status endpoint conveys a pool’s desired size at the moment, along with other information about the pool, as a JSON document.
Accessing the endpoint requires an access key provided via an Authorization: Bearer «access-key» HTTP header, with the user having the Test Distribution permission. It can also be accessed in a browser when signed in to Develocity and having the Test Distribution permission.
To create an access key, log into Develocity and go to https://«hostname»/settings/access-keys and click on the Generate button.
The following demonstrates using curl to access the endpoint:
$ curl -H "Authorization: Bearer «access-key»" https://«hostname»/api/test-distribution/agent-pools/«pool-id»/statusWhich will produce output of the following form:
{
"id": "«pool-id»",
"name": "Linux",
"capabilities": [
"jdk=11",
"os=linux"
],
"minimumAgents": 1,
"maximumAgents": 100,
"connectedAgents": 25,
"idleAgents": 9,
"desiredAgents": 16
}Auto scalers need only consider the desiredAgents field and adjust the number of running agents to match this number.
The old https://«hostname»/distribution/agent-pools/«pool-id» endpoint is deprecated and will be removed in a future release. See Querying pool status (2022.3 and earlier) for its documentation. |
Historical usage
The Usage tab provides a historical overview of workload in terms of number of active jobs, agent utilization, and agent pool metrics, for the last hour, 24 hours, or 7 days.
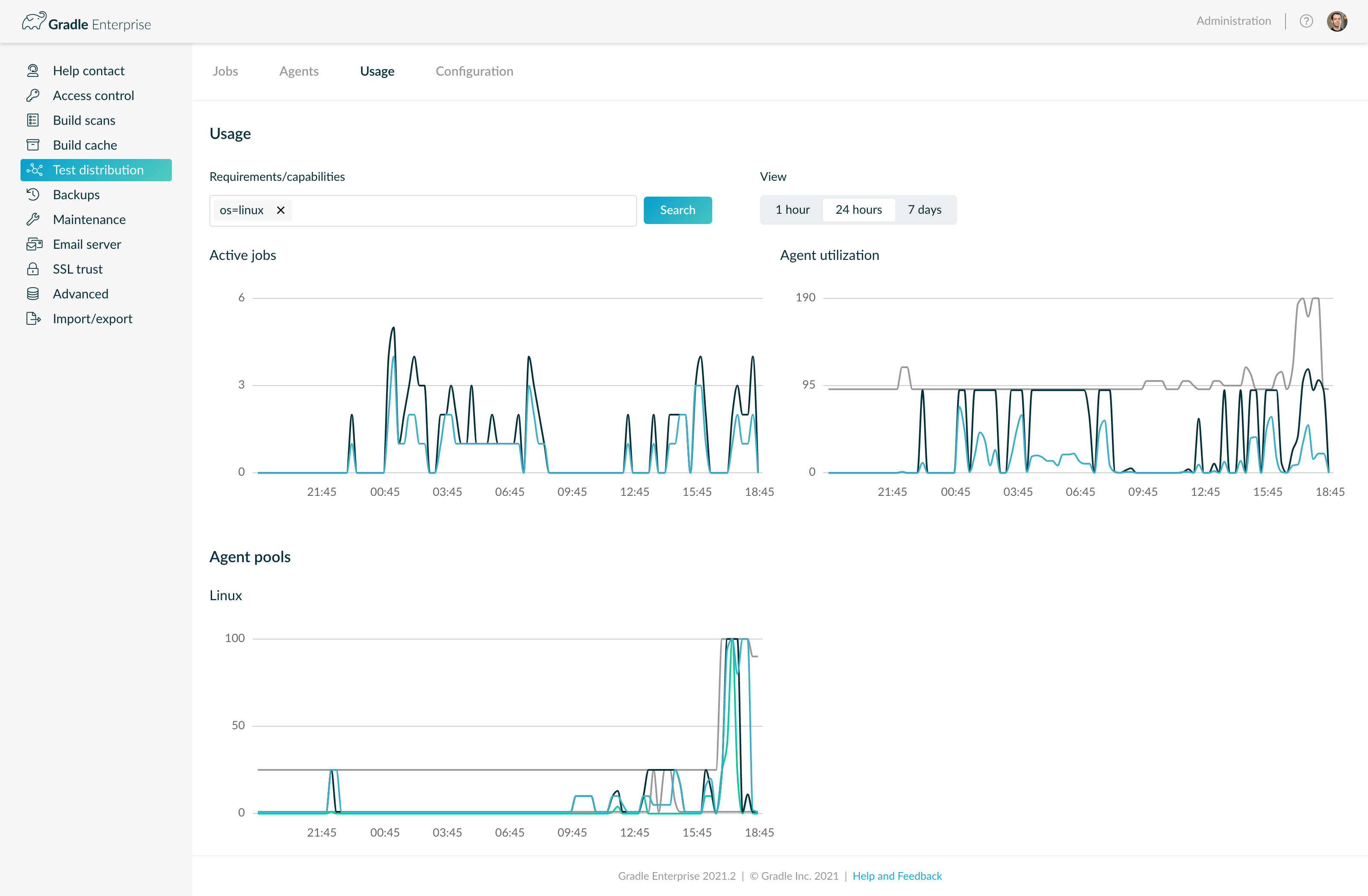
By default, all jobs, agents, and agent pools are shown. Adding requirement/capability criteria shows only the jobs with at least the specified requirements, only the agents with at least the specified capabilities, and only the agent pools with at least the specified capabilities.
Predictive Test Selection
Develocity Predictive Test Selection allows developers to get faster feedback by running only tests that are likely to provide useful feedback on a particular code change using a probabilistic machine learning model. It is available for Gradle and Apache Maven™ builds.
Builds that have enabled Predictive Test Selection connect to Develocity to select relevant tests. Develocity users must be granted the “Use Predictive Test Selection” access control permission to be able to use Predictive Test Selection. For information on how to use Predictive Test Selection, please consult the Predictive Test Selection User Manual.
Appendix A: Upgrade notes
Please see the Develocity Upgrade Guide.
Appendix B: Develocity distributions
Develocity comes in two distribution options. These are referred to as the Develocity standalone distribution and the Develocity Kubernetes distribution. You might notice that the two installation manuals (standalone, Kubernetes) are named accordingly.
To find out which installation you are using, you can check the name of the Helm chart you used to install Develocity by e.g. looking at the output of helm ls --namespace <the namespace where your Develocity instance is installed>. The Helm chart for your installation will be prefixed with "gradle-enterprise-standalone" if you are using the standalone distribution, whereas it will be prefixed only with "gradle-enterprise" if you are using the Kubernetes distribution.
Standalone distribution
The standalone distribution is an installation of Develocity that runs on a single host, using K3s, a lightweight Kubernetes distribution. It is designed for administrators who want an "out-of-the-box" experience.
Kubernetes distribution
The Kubernetes distribution is an installation of Develocity that is intended for use by organisations with existing Kubernetes infrastructure and administrators who are comfortable operating a Kubernetes cluster.
Appendix C: Unattended configuration
Administrators often need to configure and deploy applications without user intervention. Develocity enables unattended configuration with scripts and configuration management tools, such as Helm.
Develocity applies a unique unattended configuration only once, then stores it in the database. Configuration changes made with the Develocity UI persist between startups unless the configuration file is updated and applied, typically by an upgrade. When configured for unattended configuration, Develocity starts up with the configuration file stored in the database.
Making changes to the unattended configuration file will overwrite any configuration changes made in the user interface when it is applied with a helm install or helm upgrade command. If you make configuration changes in the user interface, be sure to update your unattended configuration file so that important settings are not lost the next time it is applied. |
Administrators may export their current configuration and then re-import later to roll back to a prior state and restore configuration changes. If you keep a copy of your Develocity configuration for disaster recovery or creating test installations, you should regularly export your configuration from your instance, or have a policy that disallows changing settings via the UI.
Configuring Develocity for unattended configuration
Administrators configure Develocity by running the helm install or helm upgrade command and passing the configuration options in one of two files:
-
values.yaml -
unattended-config.yaml
The first option is the Helm configuration file, values.yaml. Include the unattended configuration under the global.unattended.configuration property. If the file contains encrypted secrets, include the key under the global.unattended.key property. The second option is also a well-formed .yaml file, but of any name and passed to Helm commands as the global.unattended.configuration Develocity CLI option. Unlike using values.yaml, an encryption key cannot be included in an unattended configuration file, but must also be passed to Helm as a CLI option. Changes made to an unattended configuration file are not applied to Develocity until the administrator runs the helm install or helm upgrade command. For examples, see the Develocity Kubernetes Helm Installation Manual for Kubernetes cluster installations or the Develocity Helm Standalone Installation Manual for installation onto a single host.
Administrators may use separate methods to pass the configuration and key. They may opt to provide the configuration in values.yaml, but pass the key separately with the global.unattended.key CLI option. They may also opt to provide the configuration in an unattended configuration file set with the global.unattended.configuration CLI option, but pass the key separately in values.yaml.
When editing the file, use the latest JSON schema for code completion and validation. You can also use schemastore support on your preferred editor. In addition, administrators may validate their configuration file by running the config-file validate command from the latest Develocity Admin CLI tool. |
The easiest way to get a functional configuration yaml file is to download the Develocity configuration file from a running installation by visiting the Administration page>, then navigating to Import/export and then Export. Below is an example of minimal, valid Develocity configuration file with only the two required properties, the configuration schema version and the hashed password of the system user.
version: 9
systemPassword: XXXXXXXXXXXXXX==See Develocity config reference for other common properties.
Hashing the system password
To hash the value for the system password, use the Develocity Admin CLI config-file hash command:
$ echo "secret-password" | develocityctl config-file hash -o secret.txt -s -$ cat secret.txtJPUFnmELA2i39tDNWSdhCizAfooGr/+5Nf6syHEt73w==
|
If using the Docker form of the Develocity Admin CLI, the shell alias recommended in the guide does not allow piping input as above. To make it work, omit the |
| If you encrypted secrets in the file with a key, keep this key available to provide to Helm. |
Encrypting secret values
The system password must be hashed, but other secrets in this file can optionally be symmetrically encrypted. It is recommended to use only plain text for secrets if the values will be securely injected as part of your automation. Encrypted values will have a prefix of aes256:, as shown in the snippet from a configuration file below:
email:
authentication:
password: aes256:aExYdWTRU24ZZ4Yo:wKcjYYRJajU4J4B5:Uz66aGkDDZqI2kNQ81mj4/q1oyi2Q88=Secrets that are included in the configuration file as plain text must be prefixed with “plain:”, as shown in the snippet from a configuration file below:
email:
authentication:
password: plain:MySecretPasswordThe Develocity Admin CLI can be used to generate a new encryption key, and to encrypt secret configuration values using the generated key.
$ develocityctl config-file generate-key -o key.txt
$ echo "secret_value" | develocityctl config-file encrypt -k key.txt -o encrypted.txt -s -$ cat key.txtaes256:7l1odtTnuza0B9aa:1q2Bx/E7yz1zronpuJpOxAsgos5qpq4CtDsE2K5QnRs=
$ cat encrypted.txtaes256:7l1odtTnuza0B9aa:VFVkWB9OBsXz79Ue:njXgHpQJIVDCkqZgUUJXl6X2eItkJndW4vT762TesaY=
Configuration values which are applicable for encryption have the type EncryptedSecret in the JSON schema.
Admin CLI Docker image usage
As with hashing values, if using the Docker form of the Develocity Admin CLI, the shell alias recommended in the guide does not allow piping input as above. To make it work, either omit the key and secret from the command and enter the values interactively:
$ develocityctl config-file generate-key -o -aes256:bCy08OAN8tIbwMbW:EobFycmy1VtAGX/0motfSpVZzex3cHHf4sr6pmOrwWo=
$ develocityctl config-file encryptEnter key: Enter secret:
aes256:bCy08OAN8tIbwMbW:XbOx4IFZ/LtMBINV:RZ4z75rcl0F94WSyIljRd/a8aw==
Or run the Docker command directly:
$ develocityctl config-file generate-key -o - > key.txt
$ echo "secret-password" | docker run --rm -i -v $(pwd)/key.txt:/key.txt \
gradle/develocityctl config-file encrypt -k /key.txt -o - -s -aes256:bCy08OAN8tIbwMbW:XbOx4IFZ/LtMBINV:RZ4z75rcl0F94WSyIljRd/a8aw==
Migrating a configuration file to a new schema version
When administrators want to enable a configuration setting not supported by their current version of the application, they must update the configuration file for the latest schema version. Migrating a configuration file to an updated schema version by hand is difficult. However, Develocity automatically updates every exported configuration file to the latest version of the schema.
To automatically migrate a configuration file to an updated schema:
-
Upgrade to the newer version of Develocity with the desired configuration setting.
-
Export the configuration file using the UI.
-
Edit the file for the new setting.
-
Set the
global.unattended.configurationCLI option to the updated unattended configuration file. -
Check your configuration file into source control.
Appendix D: Develocity config reference
The JSON schema describes all configuration options. Some common settings are described in more detail here.
Additionally, you can learn more about what these configuration options do by reading above, and exploring the administration page of your Develocity instance.
| Attribute | Description |
|---|---|
|
|
Required. |
|
|
Required. |
|
|
Every day, Develocity runs maintenance operations on the database to keep things running smoothly. This maintenance temporarily effects Develocity’s performance, so you should set this to a time of day (UTC) in which you anticipate low build scan ingest traffic. |
|
|
A newline-separated list of certificates which Develocity should trust when communicating with servers using certificates not trusted by default, for example if they are signed by an internal CA. |
|
|
The protocol used to connect to the proxy. Supported values are |
|
|
HTTP proxy host name. |
|
|
HTTP proxy port. |
|
|
A comma-delimited list that controls what hosts should not be proxied. The list can contain individual host names as well as domain patterns (e.g. '*.internal') which match all hosts for a particular domain. Any requests sent to these hosts will be sent directly rather than being sent through the HTTP proxy. |
|
|
A username used to authenticate with the HTTP Proxy. |
|
|
A password used to authenticate with the HTTP Proxy. |
|
|
Some events related to Develocity may warrant a notification to the administrators of your installation. For example, if your installation’s disk space is running low, or if a backup was created. The |
|
|
Determines the permissions of users of your Develocity instance who are not logged in. For example, you may want only authenticated developers to be able to publish build scans, in which case you should not enable the |
|
|
Configures the roles that can be used to assign permissions to users, and how those roles are mapped from any external identity providers. For example, you could create a |
|
|
Configures external identity providers, using either LDAP or SAML. For example, your organisation might use a Google or Microsoft product to manage permissions for all tools centrally and globally. You can configure |
|
|
Can be set to one of
|
|
|
You should only configure any values under |
Build Scans object storage Develocity configuration reference
To configure Develocity to store incoming Build Scan data in object storage, add the following snippet to your configuration file:
buildScans:
incomingStorageType: objectStorage| If using a static Access Key ID / Secret Access Key pair, you should first encrypt the secret key. |
You should increase the heap memory allocated to the Develocity application. If you already have a heap memory setting, increase this by 2048. If you do not, set the value to 5632 by adding the following snippet to your configuration file:
advanced:
app:
heapMemory: 5632You will also need to increase Develocity’s memory requests and limits by the same amount in your Helm values file:
enterprise:
resources:
requests:
memory: 6Gi (1)
limits:
memory: 6Gi (1)| 1 | If you have already set a custom value here, instead increase it by 2Gi. |
If you are using EKS service account based credentials, ensure that you have configured Helm with the necessary service account annotation and redeployed.
Deprecated S3 bucket prefix configuration
Releases prior to 2023.2 allowed specifying a prefix to use within a bucket when storing Build Scan data. This is now deprecated, and all Build Scan data will be stored under the prefix build-scans, which was the previous default value used if not specified.
Installations that store significant Build Scan data under a custom prefix can add that prefix as an advanced app parameter by adding the following snippet to your configuration file:
advanced:
app:
params:
buildScanStorage.prefix: my/prefixThis override will be removed in a future release. Administrators using a custom prefix are encouraged to copy their data to the build-scans prefix and remove the override.
Migrating Build Scan data to the standard prefix
To migrate Build Scan data to the standard build-scans prefix, follow these steps:
-
Decide on a copying strategy. A basic approach suitable for < 10GB of data would just use the AWS CLI s3 sync command, something like
aws s3 sync --delete s3://example-bucket/custom-prefix s3://example-bucket/build-scans. This AWS resource lists strategies suitable for transferring larger volumes of data. Ensure that the strategy chosen will allow deleting files from the destination if they are not at the source. -
While the app is running, copy most data to the new location by running the copy process chosen.
-
If configuring through the UI, remove the
buildScanStorage.prefixadvanced parameter described above. Save and restart the app if prompted. -
Stop the Develocity by running the Develocity Admin CLI
system stopcommand, or by manually scaling all deployments to zero. -
Run the copy process again to sync any last additions and deletions.
-
If configuring through unattended configuration, remove the
buildScanStorage.prefixadvanced parameter described above and rerunhelm upgrade. This should restart the app. Further details can be found in the “Changing configuration values” section of the Develocity Upgrade Guide. -
If configuring through the UI, restart Develocity by running the Develocity Admin CLI
system startcommand, or by manually scaling all deployments back up to their original number of replicas. -
Verify that data is in the expected place by viewing some recent Build Scan pages.
-
At this point, Build Scan data under the custom prefix can be deleted using
aws s3 rm --recursive s3://example-bucket/custom-prefixor equivalent.
Appendix E: Migrating object storage configuration to Helm
In releases prior to 2023.3, Develocity connection settings for S3 object storage were configured by the Administration interface or via unattended configuration. From Develocity 2023.3 onwards, object storage settings are configured as Helm values.
| The Administration Object Storage page referenced in the following procedure is visible in the UI only if the Develocity instance has a legacy configuration to remove. |
To migrate object storage configuration to Helm, follow these steps:
-
Add object storage settings to your Helm values file. See the Kubernetes Helm Chart Configuration Guide or Standalone Helm Chart Configuration Guide for details.
-
In the Administration Advanced page, if you have any advanced config parameters named
legacyS3.\*(e.g.legacyS3.client.maxConcurrency) for any of the apps, they need to be copied into your Helmvalues.yaml’s `objectStorage.s3.advancedParamsfield, making sure to remove thelegacyS3.prefix from the advanced parameter name when copying them. See the Kubernetes Helm Chart Configuration Guide’s object storage advanced params section or the Standalone Helm Chart Configuration Guide’s object storage advanced params section for examples of how that should look in your Helmvalues.yamlfile. -
If you were using unattended configuration to configure object storage previously, edit your unattended configuration file in the way described below.
-
For version 8 configuration used by Develocity 2023.3, remove the top-level
legacyObjectStorage. If you are using any advanced parameters, remove any namedlegacyS3.*(e.g.legacyS3.client.maxConcurrency) fromadvanced.\*.params(e.g.advanced.app.params). -
For version 7 configuration used by Develocity 2023.2, remove the top-level
objectStoragenode. -
For configuration versions 5 and 6 used by Develocity versions 2022.3-2023.1, remove the
buildScans.storage.s3node.
-
-
Redeploy Develocity by running
helm upgrade. See Changing standalone configuration values or Changing Kubernetes configuration values. -
Verify that you can list and view new Build Scans.
-
If you use the Administration interface to configure object storage:
-
Navigate to the Administration Advanced page. If you have any advanced parameters named
legacyS3.\*(e.g.legacyS3.client.maxConcurrency) for any of the apps, delete them, and press save, but don’t restart yet. -
Navigate to the Administration Object Storage page.
-
Remove the configuration using the button labelled
Remove legacy S3 configuration. -
Restart when prompted.
-
-
Verify that you can list and view new Build Scans.
Appendix F: Develocity config schema downloads
-
gradle-enterprise-config-schema-9.json (SHA-256 checksum, PGP signature, PGP signature SHA-256 checksum)
-
gradle-enterprise-config-schema-8.json (SHA-256 checksum, PGP signature, PGP signature SHA-256 checksum)
-
gradle-enterprise-config-schema-7.json (SHA-256 checksum, PGP signature, PGP signature SHA-256 checksum)
-
gradle-enterprise-config-schema-6.json (SHA-256 checksum, PGP signature, PGP signature SHA-256 checksum)
-
gradle-enterprise-config-schema-5.json (SHA-256 checksum, PGP signature, PGP signature SHA-256 checksum)
-
gradle-enterprise-config-schema-4.json (SHA-256 checksum, PGP signature, PGP signature SHA-256 checksum)
-
gradle-enterprise-config-schema-3.json (SHA-256 checksum, PGP signature, PGP signature SHA-256 checksum)
-
gradle-enterprise-config-schema-2.json (SHA-256 checksum, PGP signature, PGP signature SHA-256 checksum)
-
gradle-enterprise-config-schema-1.json (SHA-256 checksum, PGP signature, PGP signature SHA-256 checksum)